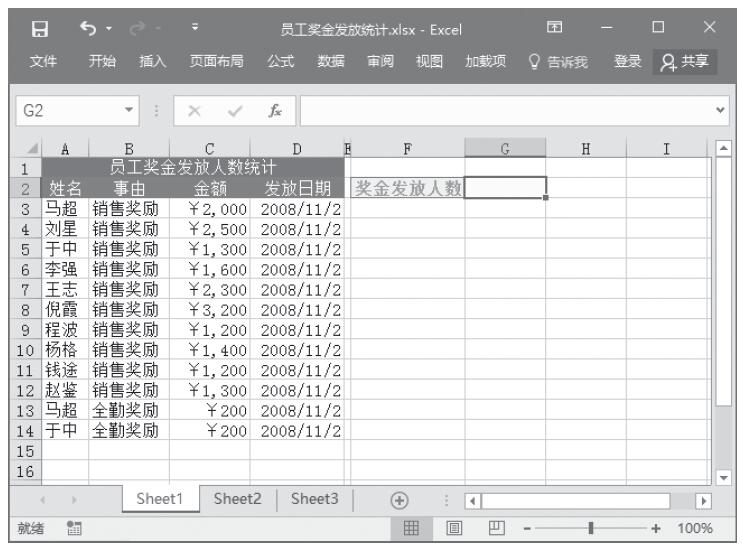
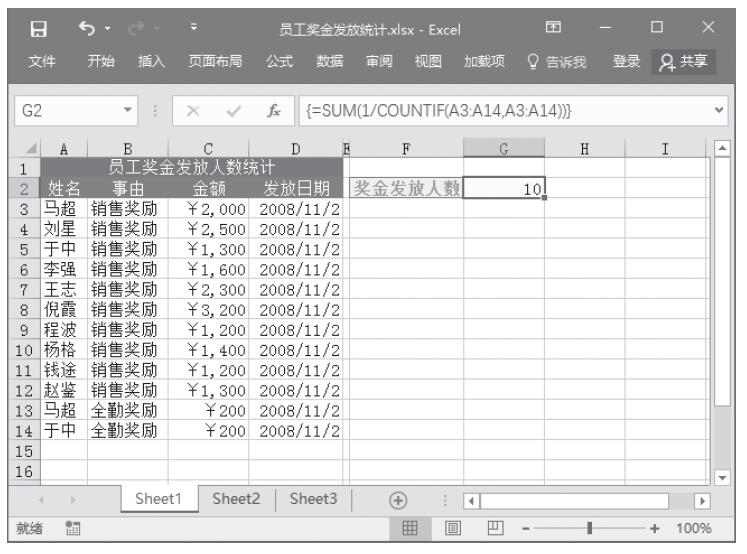
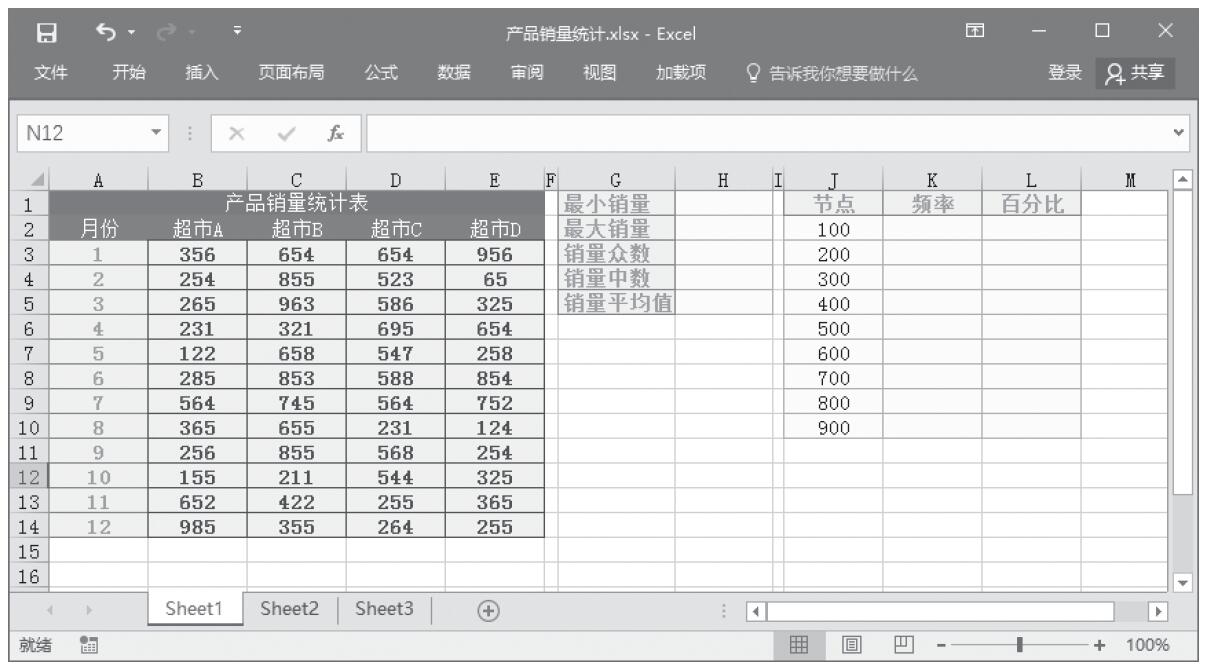
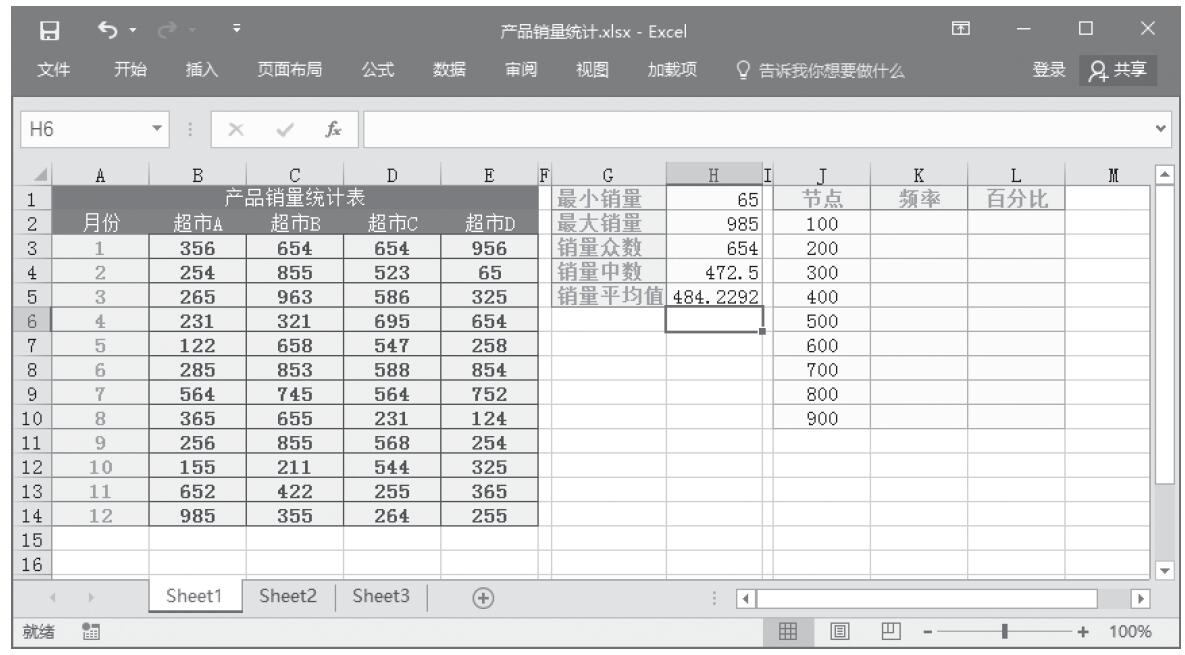
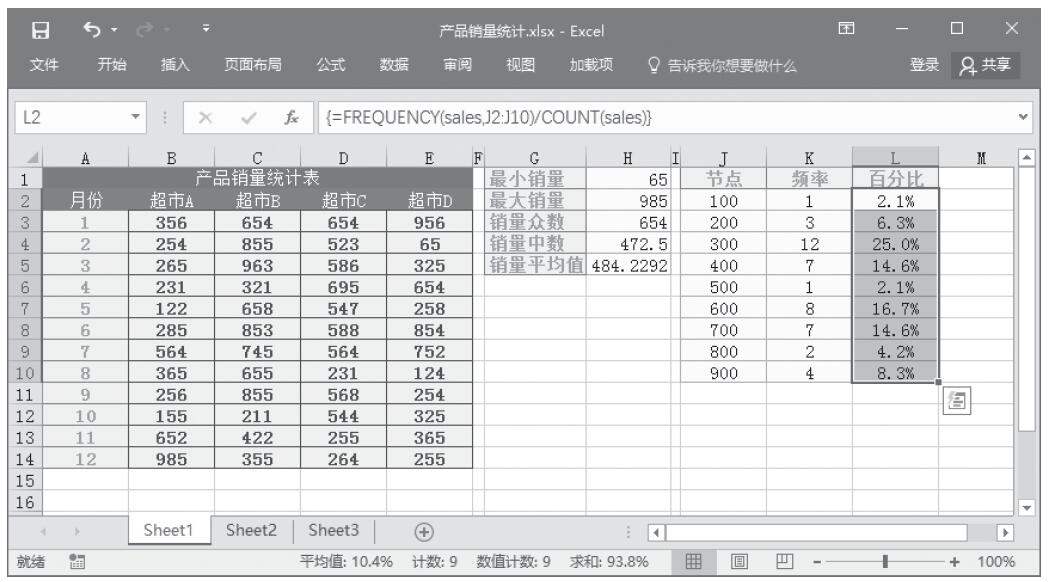
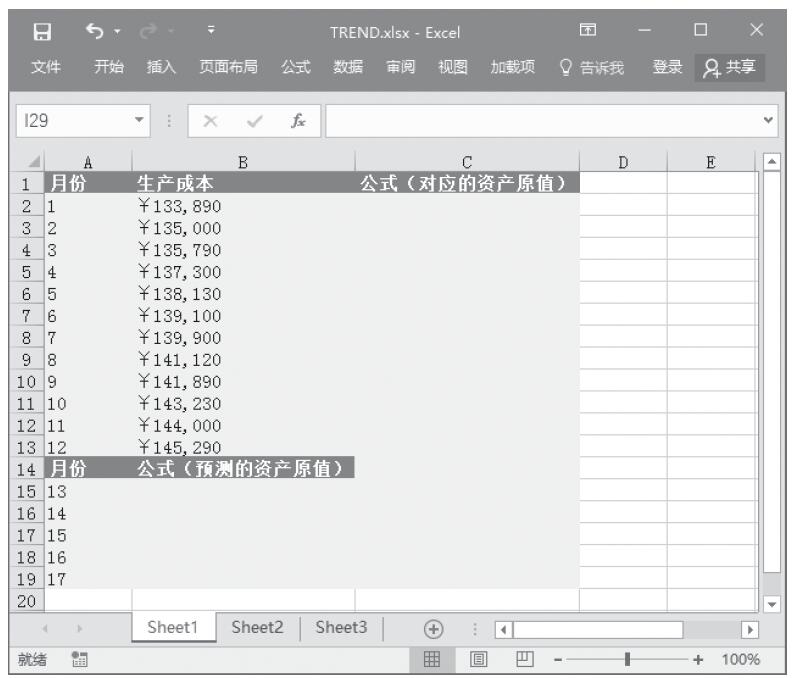
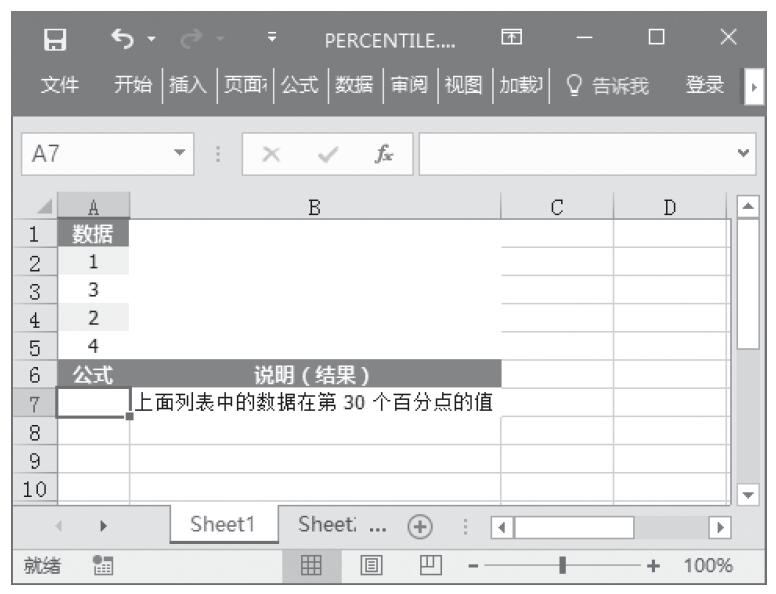
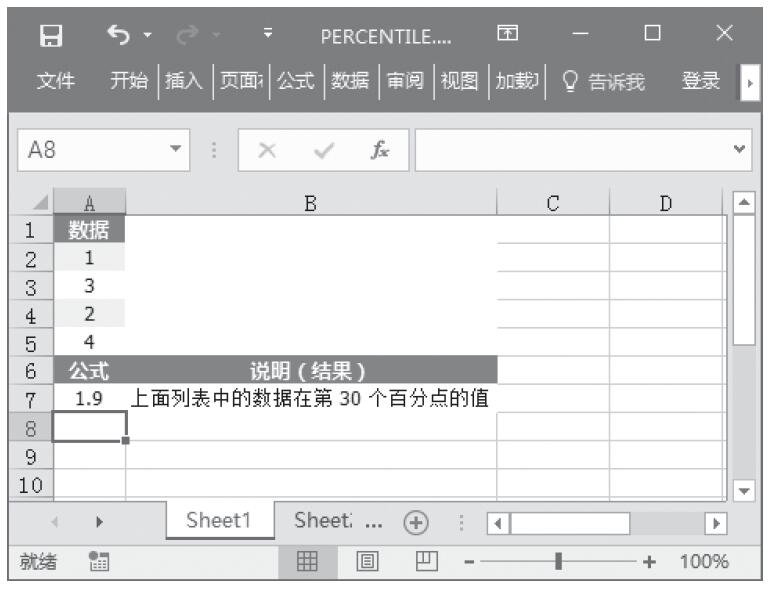
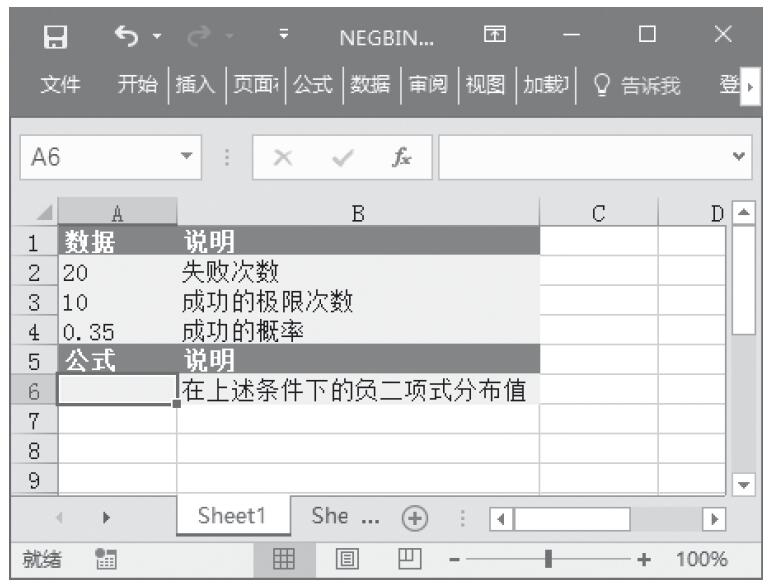
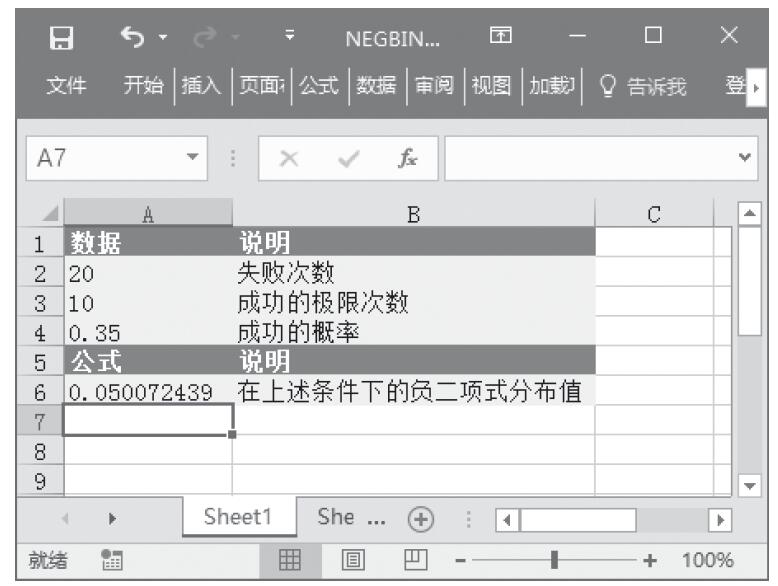
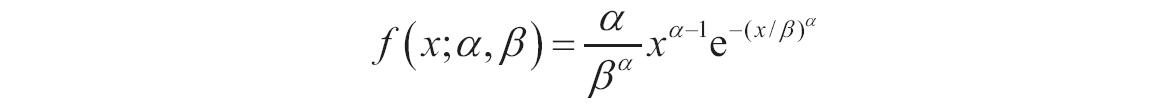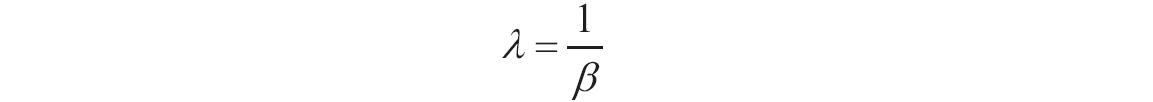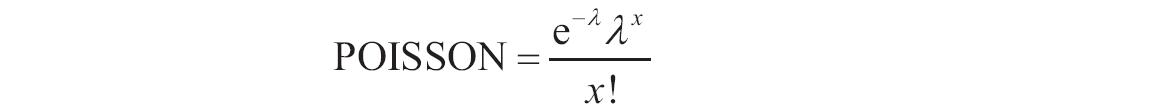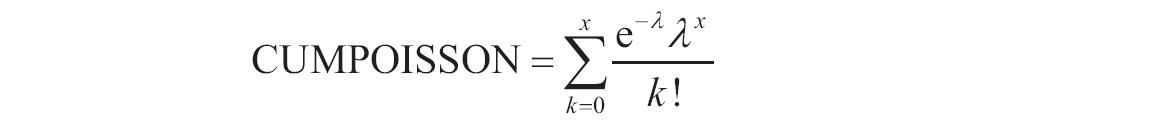某家公司向4个超市供应某种商品,统计了该商品一年中各月份在每个超市的销售量。现在欲统计商品在一年中的最小销量、最大销量、销量众数、销量中数、销量平均值,以及分段销量的频率。基础销量统计数据如图16-165所示。
图16-165 基础销量统计数据
下面根据基础销量统计数据分步详细介绍如何进行上述数据计算。
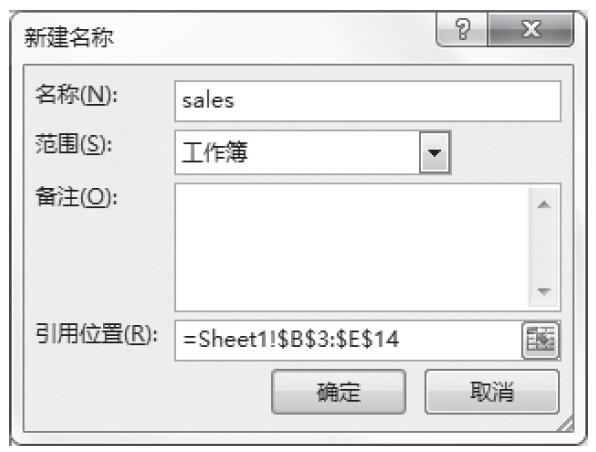
步骤1:定义数据区域。选中单元格区域“B3:E14”,然后单击“公式”选项卡中的“定义名称”按钮,打开“新建名称”对话框。
步骤2:在“名称”框中输入名称“sales”,如图16-166所示。其他选项采用默认设置。
图16-166 输入名称
步骤3:单击“确定”按钮,完成名称的定义。
步骤4:计算最小销量。在单元格H1中输入公式“=MIN(sales)”,统计一年中商品销量的最小值。
步骤5:计算最大销量。在单元格H2中输入公式“=MAX(sales)”,统计一年中商品销量的最大值。
步骤6:计算销量众数。在单元格H3中输入公式“=MODE(sales)”,统计一年中商品销量的众数。
步骤7:计算销量中数。在单元格H4中输入公式“=MEDIAN(sales)”,统计一年中商品销量的中数。
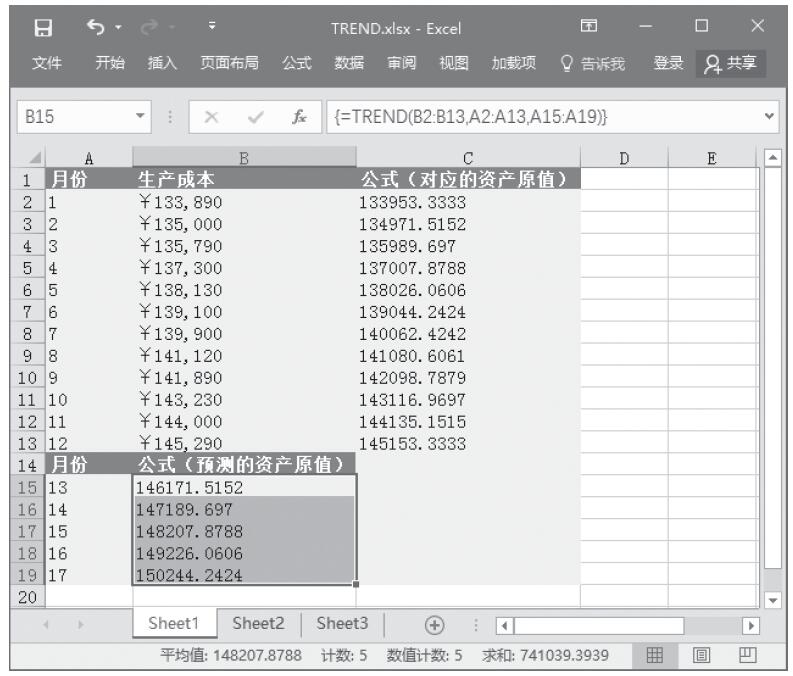
步骤8:计算销量平均值。在单元格H5中输入公式“=AVERAGE(sales)”,统计一年中商品销量的平均值。统计结果如图16-167所示。
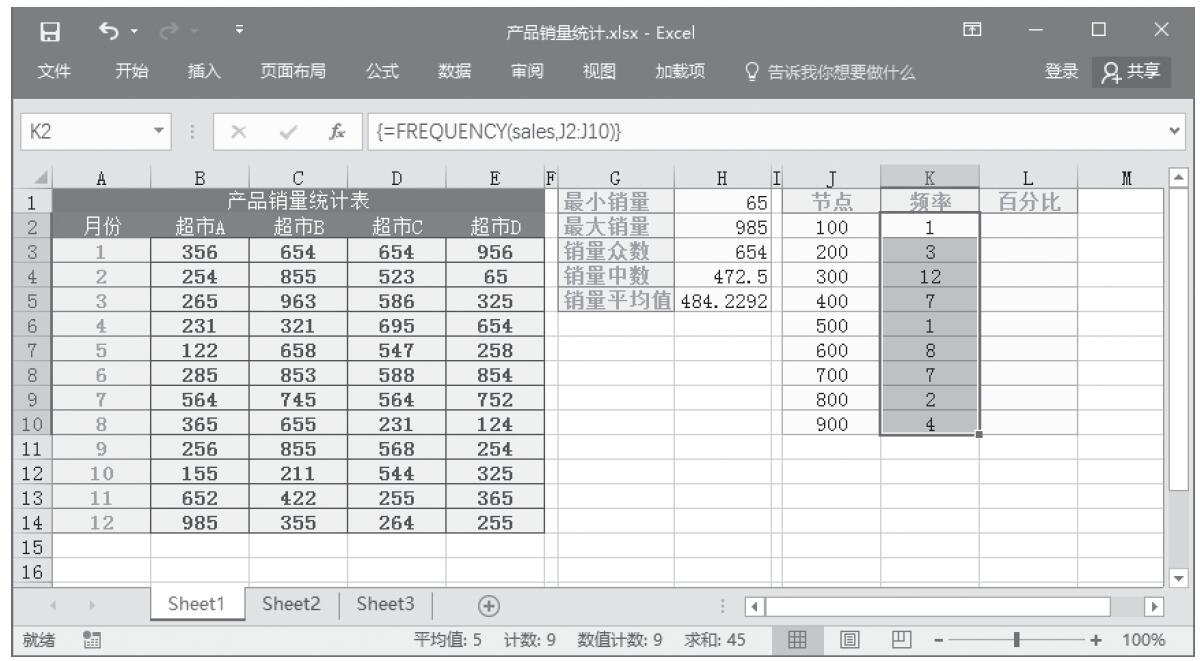
步骤9:计算分段销量的频率。选中单元格区域“K2:K10”,按F2键,然后输入公式“=FREQUENCY(sales,J2:J10)”,按“Ctrl+Shift+Enter”键以数组公式输入,结果如图16-168所示。
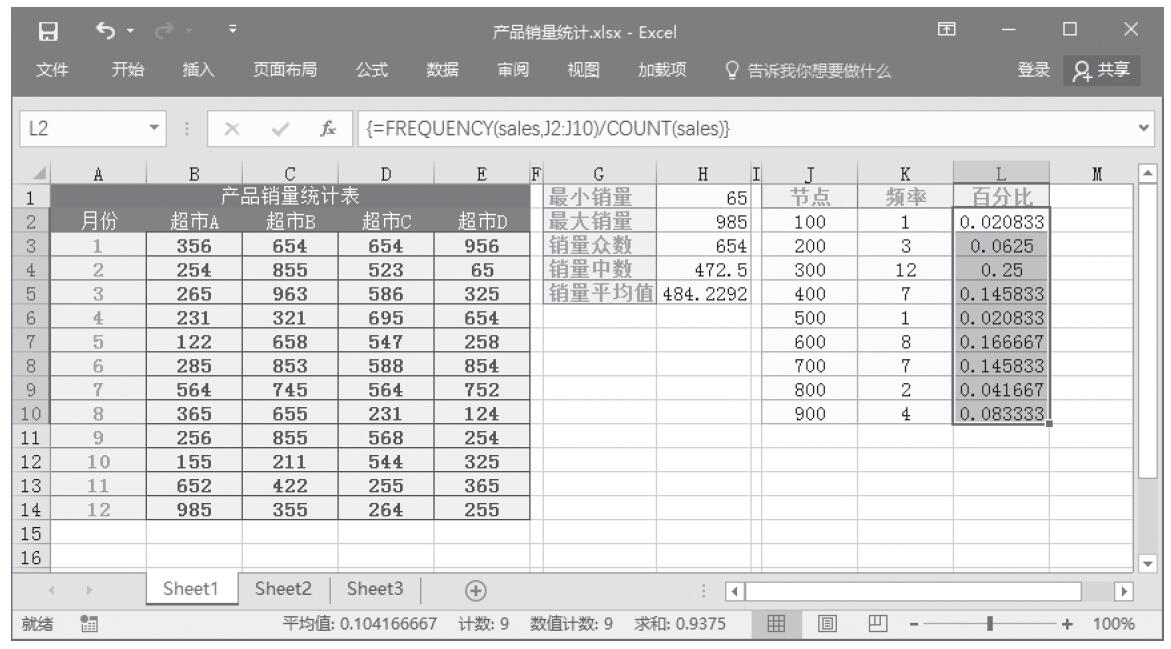
步骤10:计算分段销量的百分比。选中单元格区域L2:L10,按F2键,然后输入公式“=FREQUENCY(sales,J2:J10)/COUNT(sales)”,按“Ctrl+Shift+Enter”键以数组公式输入,结果如图16-169所示。
图16-167 统计结果
图16-168 计算分段销量的频率
图16-169 计算分段销量的百分比
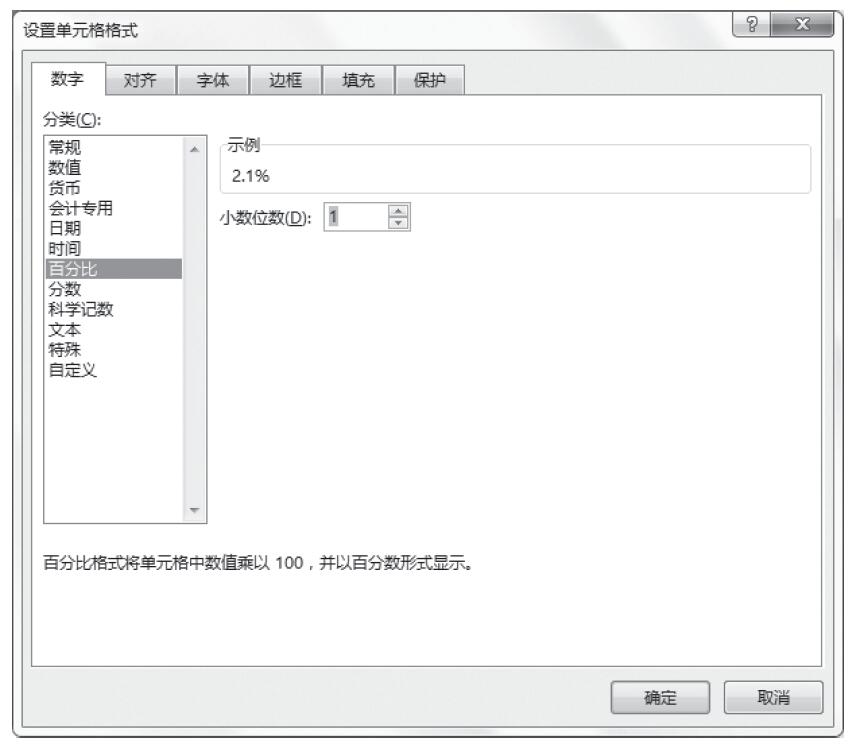
步骤11:保持单元格区域“L2:L10”的选中状态,按Ctrl+1键打开“设置单元格格式”对话框,单击“百分比”分类,然后将小数位数设置为1,如图16-170所示。
步骤12:单击“确定”按钮,得到结果如图16-171所示。
图16-170 “设置单元格格式”对话框
图16-171 分段销量的百分比