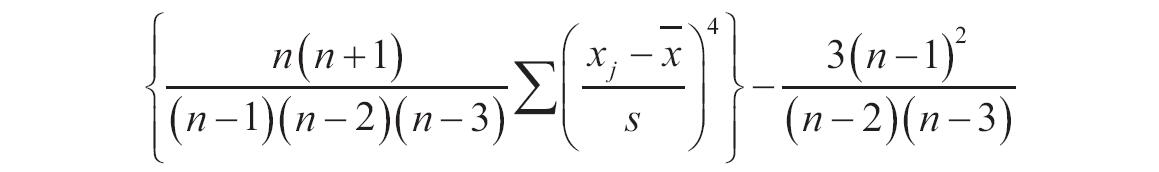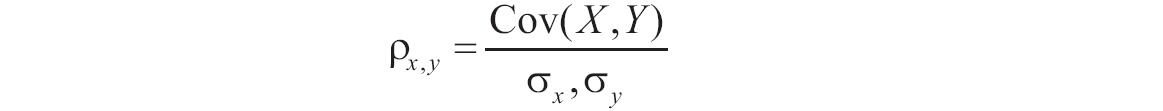TRIMMEAN函数用于计算数据集的内部平均值。函数TRIMMEAN先从数据集的头部和尾部除去一定百分比的数据点,然后再求平均值。当希望在分析中剔除一部分数据的计算时,可以使用此函数。TRIMMEAN函数的语法如下。
TRIMMEAN(array,percent)
其中参数array为需要进行整理并求平均值的数组或数值区域,percent为计算时所要除去的数据点的比例。例如,如果percent=0.2,在20个数据点的集合中,就要除去4个数据点(20×0.2):头部除去2个,尾部除去2个。
典型案例
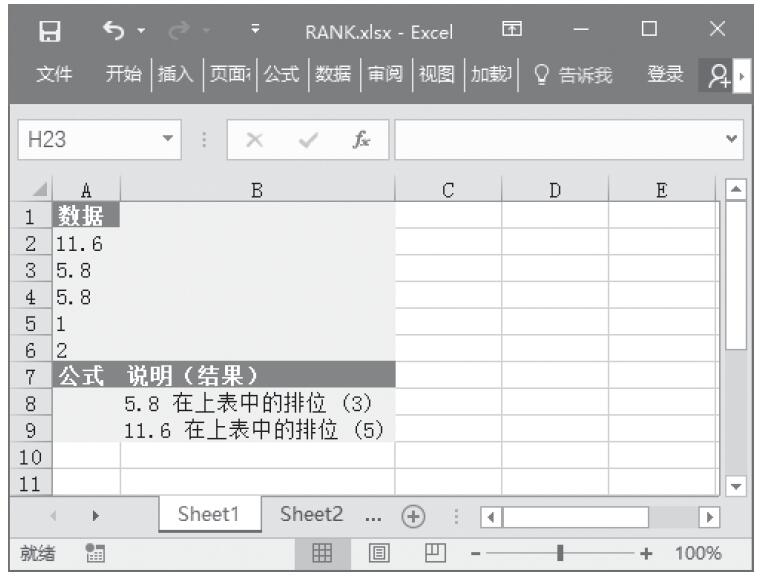
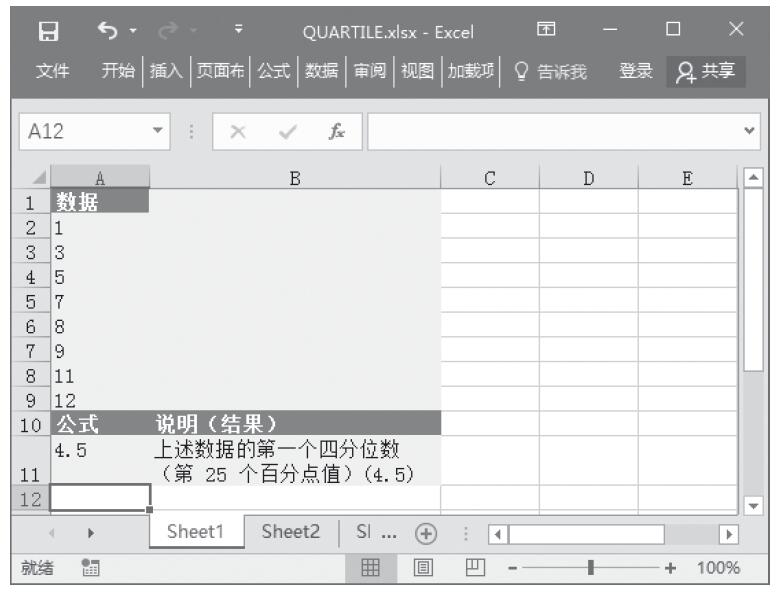
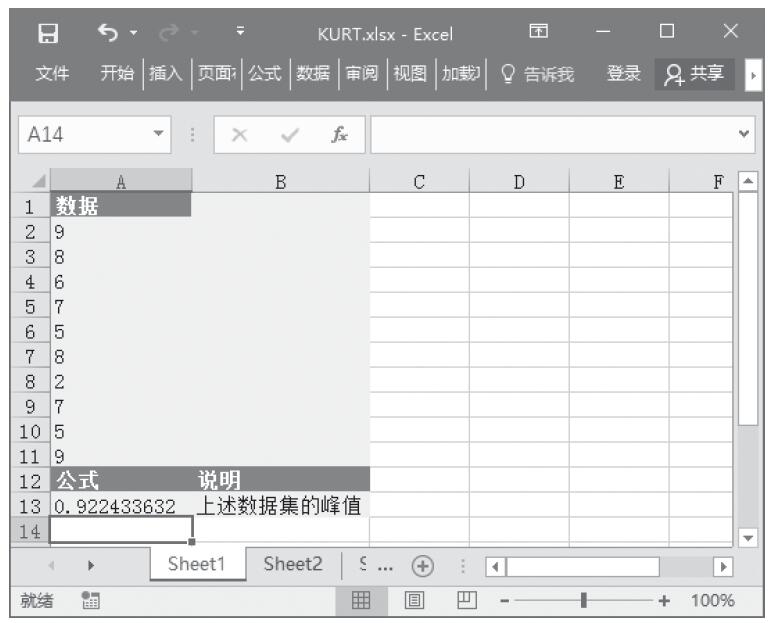
已知一组数据,计算其内部平均值。基础数据如图16-133所示。
步骤1:打开例子工作簿“TRIMMEAN.xlsx”。
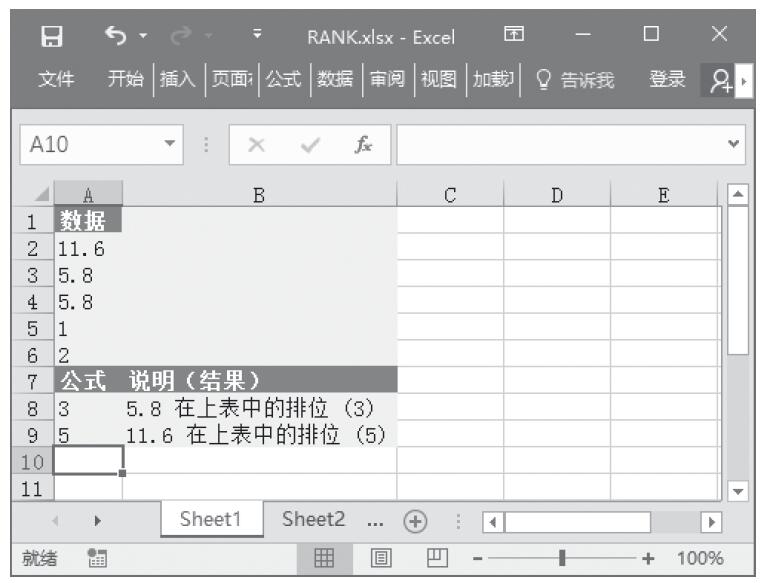
步骤2:在单元格A14中输入公式“=TRIMMEAN(A2:A12,0.2)”,用于计算数据集的内部平均值(从计算中除去20%)。计算结果如图16-134所示。
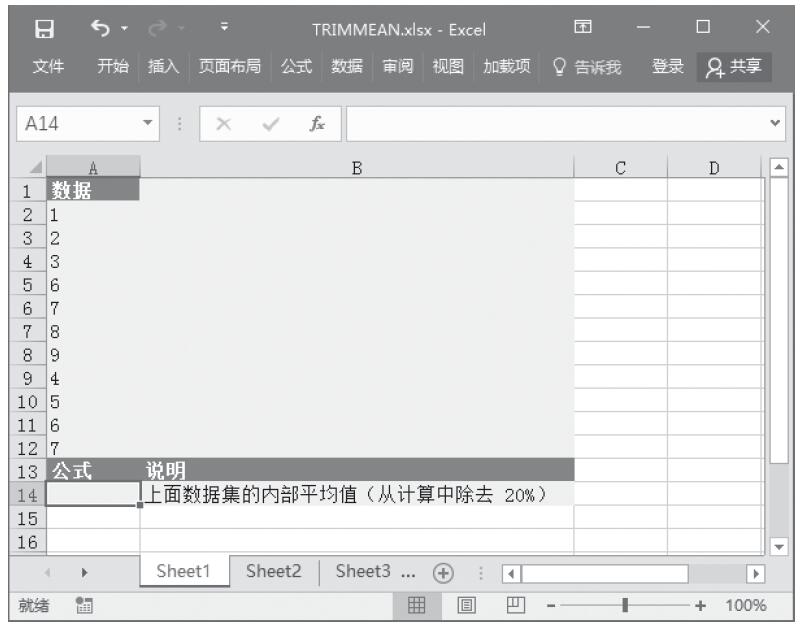
图16-133 基础数据
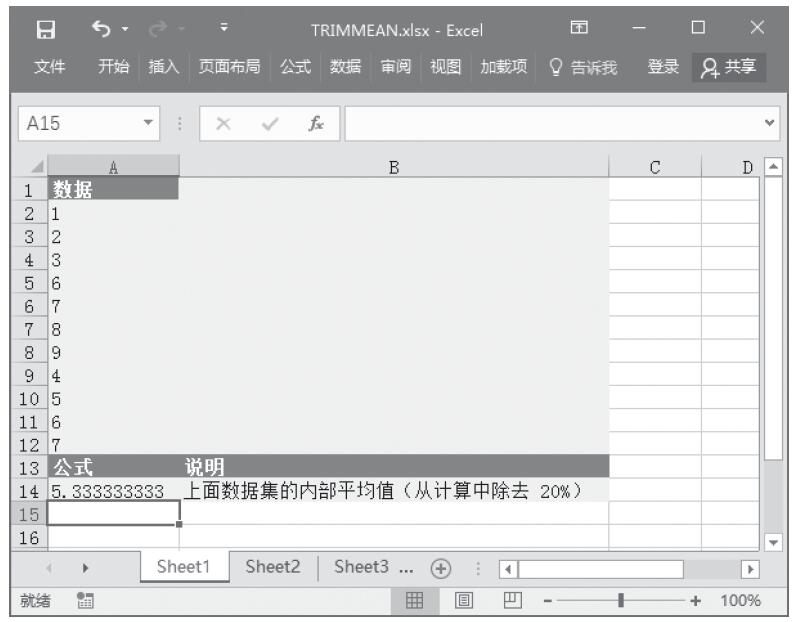
图16-134 计算结果
使用指南
如果percent<0或percent>1,函数TRIMMEAN返回错误值“#NUM!”。函数TRIMMEAN将除去的数据点数目向下舍入为最接近的2的倍数。例如,如果percent=0.1,30个数据点的10%等于3个数据点。函数TRIMMEAN将会把除去的数据点数目向下舍入为2,并对称地在数据集的头部和尾部各除去一个数据。