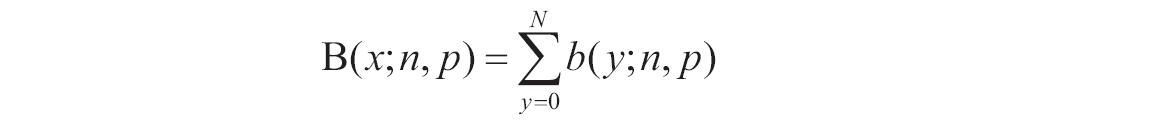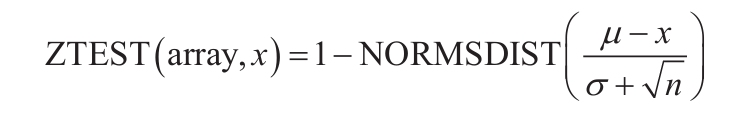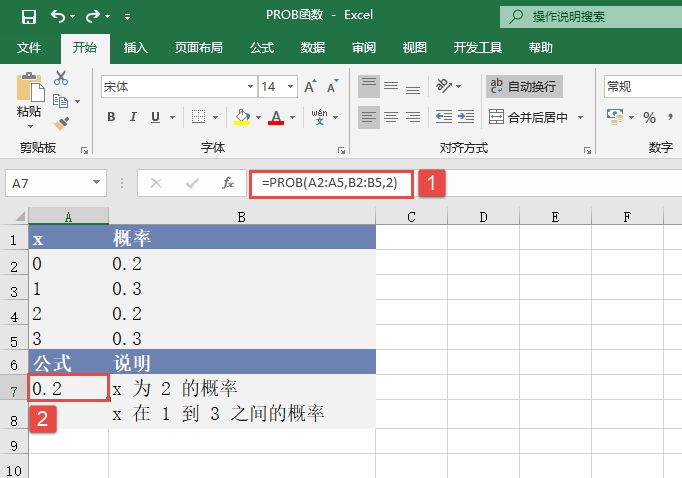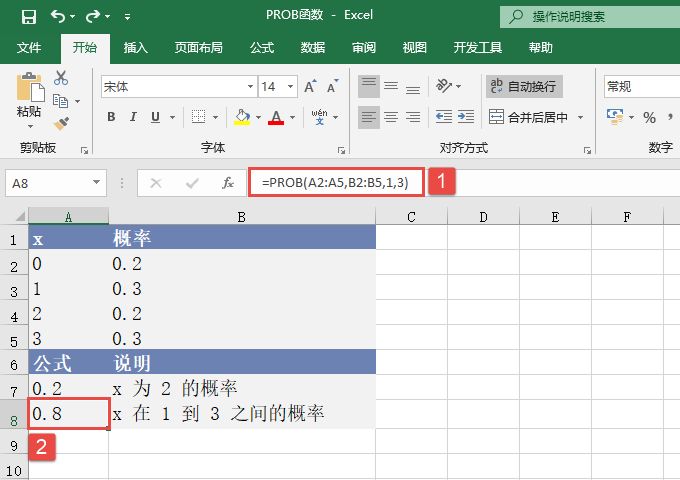
ZTEST函数用于计算z检验的单尾概率值。对于给定的假设总体平均值μ0,ZTEST返回样本平均值大于数据集(数组)中观察平均值的概率,即观察样本平均值。ZTEST函数的语法如下。

其中参数array为用来检验μ0的数组或数据区域。μ0为被检验的值。sigma为样本总体(已知)的标准偏差,如果省略,则使用样本标准偏差。
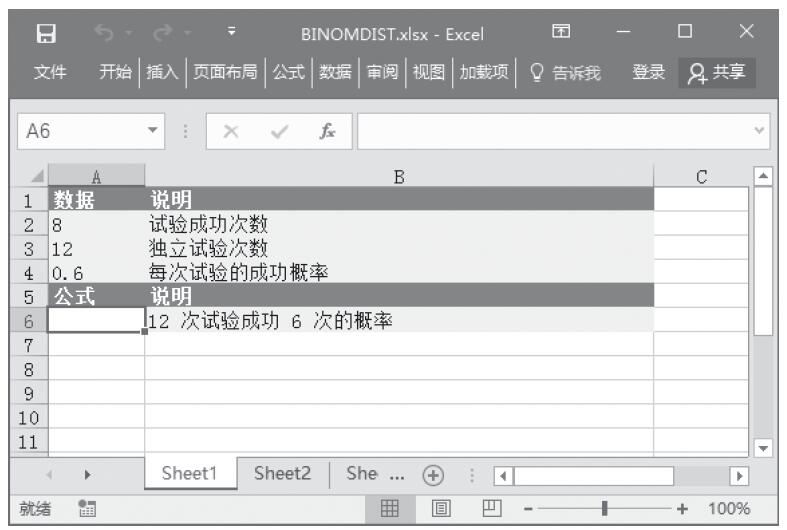
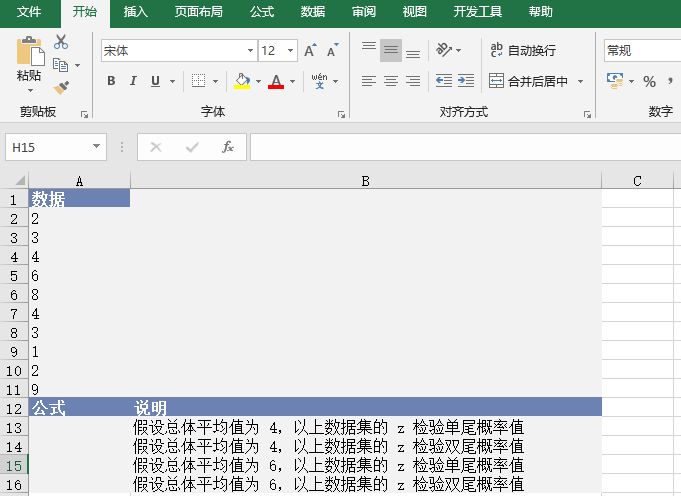
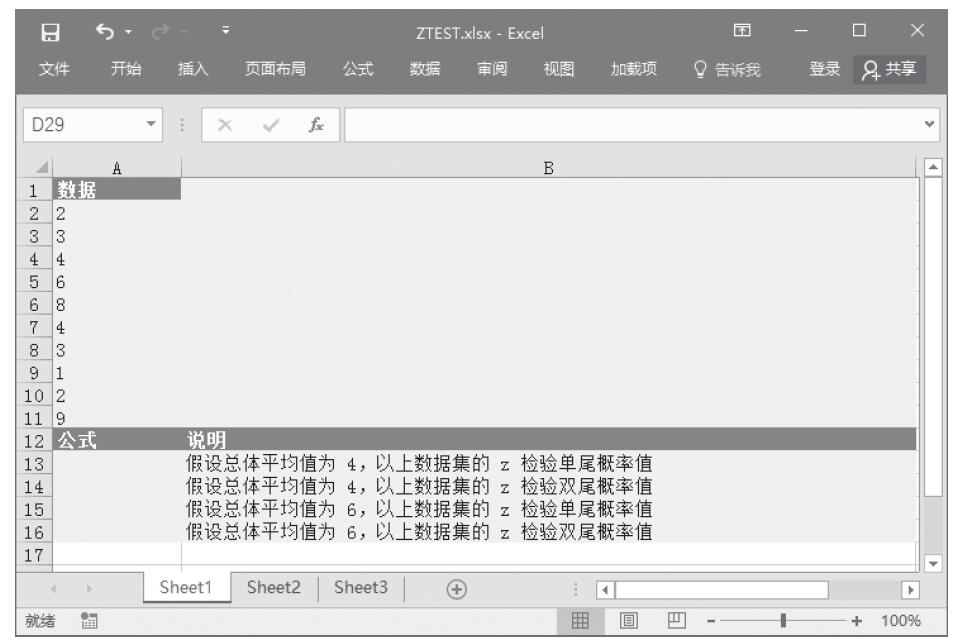
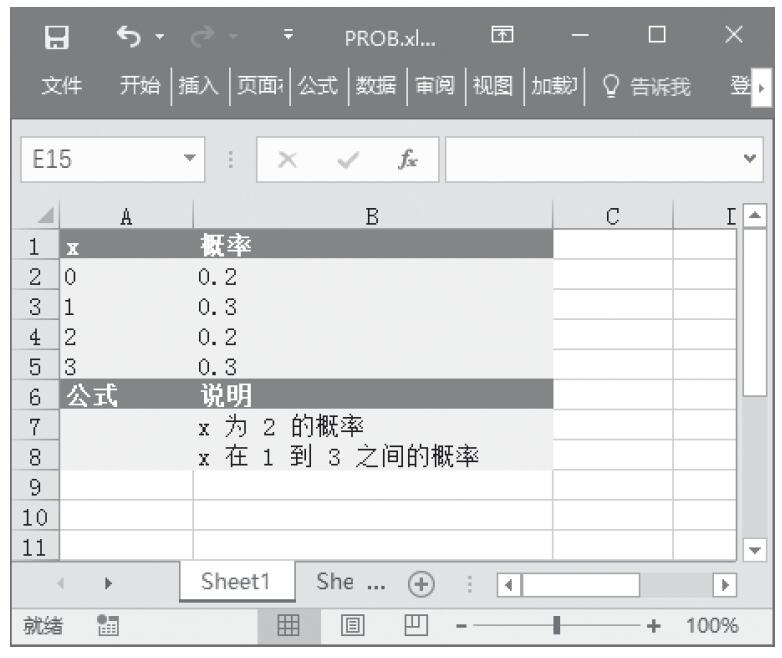
【典型案例】已知一组数据,计算z检验的单尾概率值。基础数据如图16-45所示。
步骤1:打开例子工作簿“ZTEST.xlsx”。
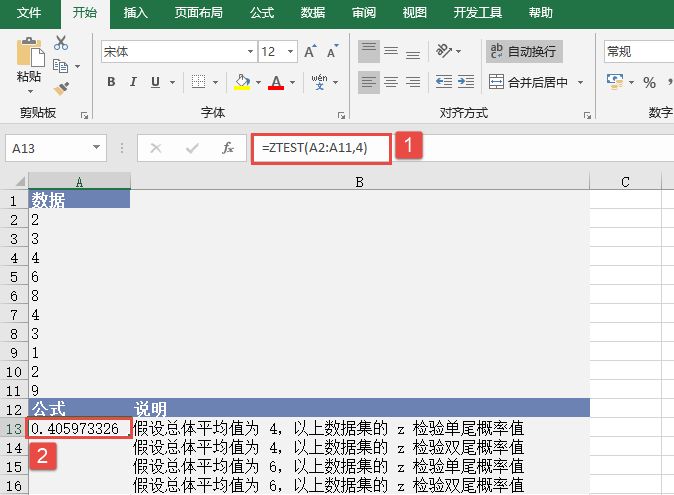
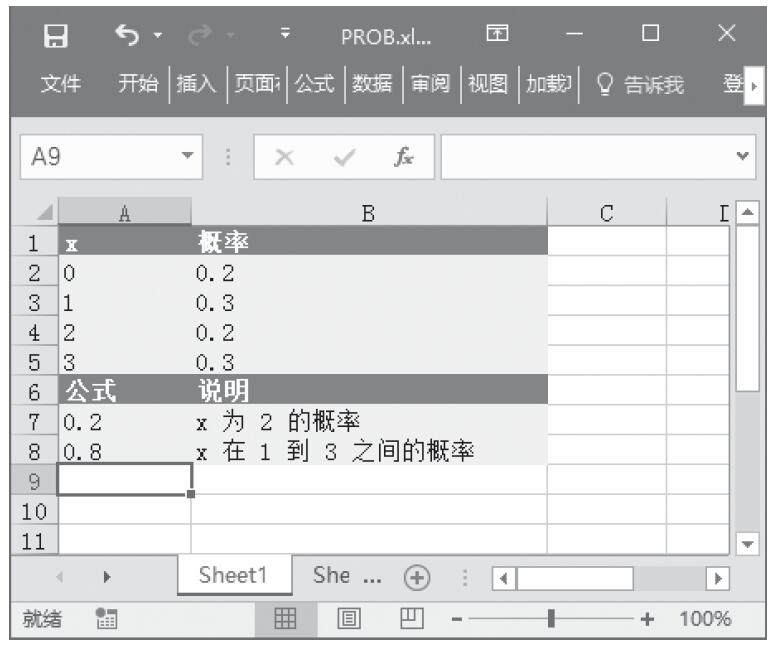
步骤2:在单元格A13中输入公式“=ZTEST(A2:A11,4)”,用于计算总体平均值为4时数据集的z检验单尾概率值。
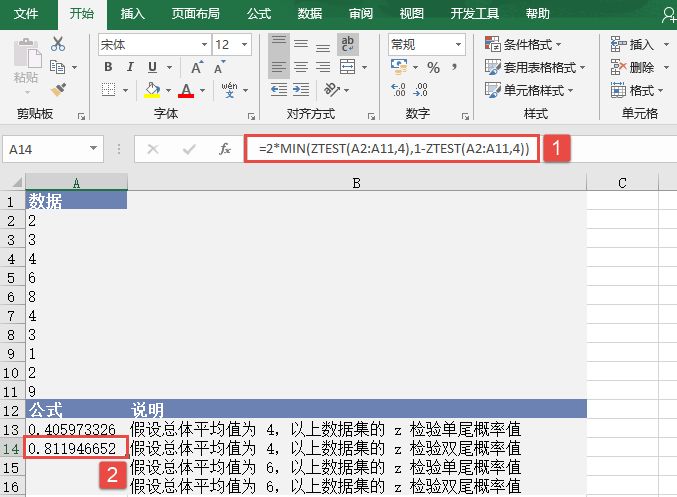
步骤3:在单元格A14中输入公式“=2*MIN(ZTEST(A2:A11,4),1-ZTEST(A2:A11,4))”,用于计算总体平均值为4时数据集的z检验双尾概率值。
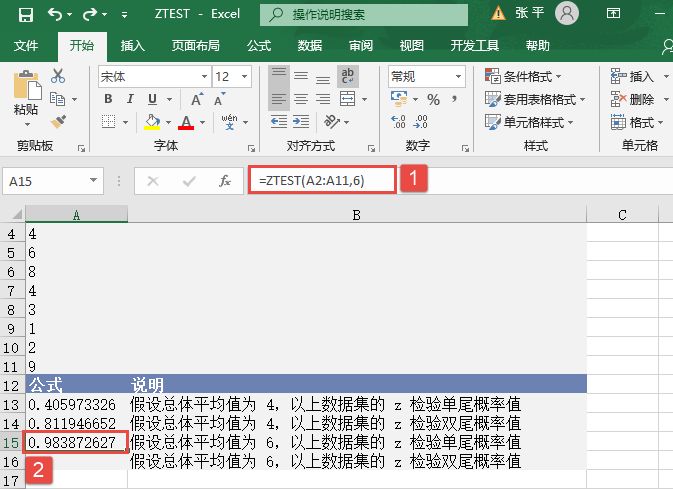
步骤4:在单元格A15中输入公式“=ZTEST(A2:A11,6)”,用于计算总体平均值为6时数据集的z检验单尾概率值。
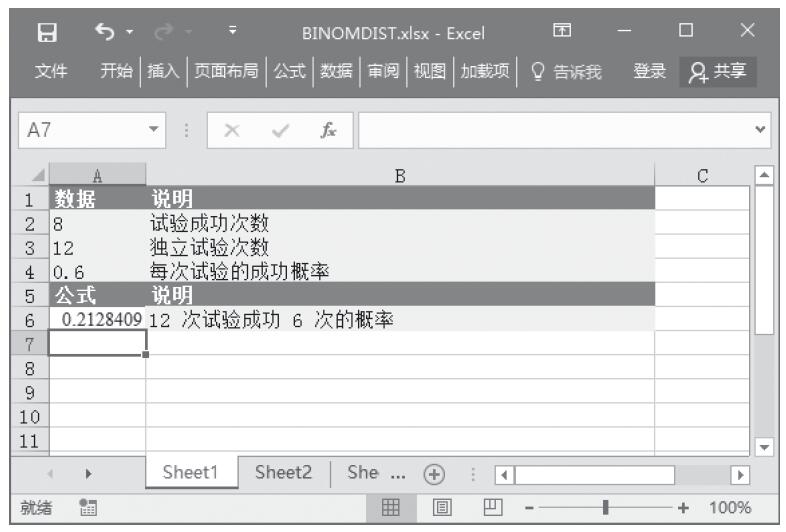
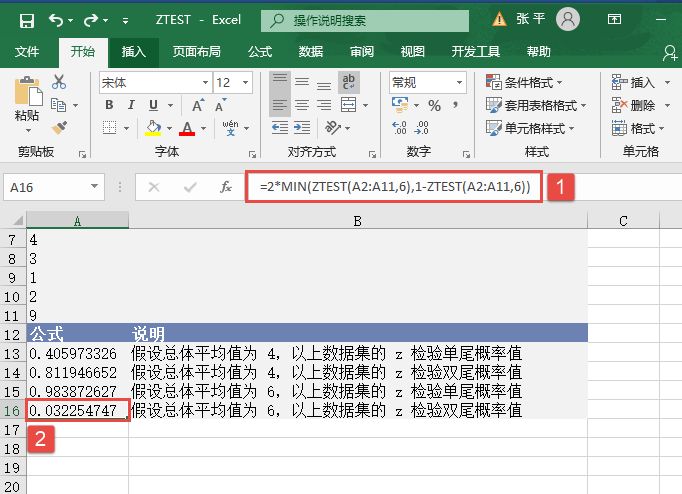
步骤5:在单元格A16中输入公式“=2*MIN(ZTEST(A2:A11,6),1-ZTEST(A2:A11,6))”,用于计算假设总体平均值为6,以上数据集的z检验双尾概率值。计算结果如图16-46所示。
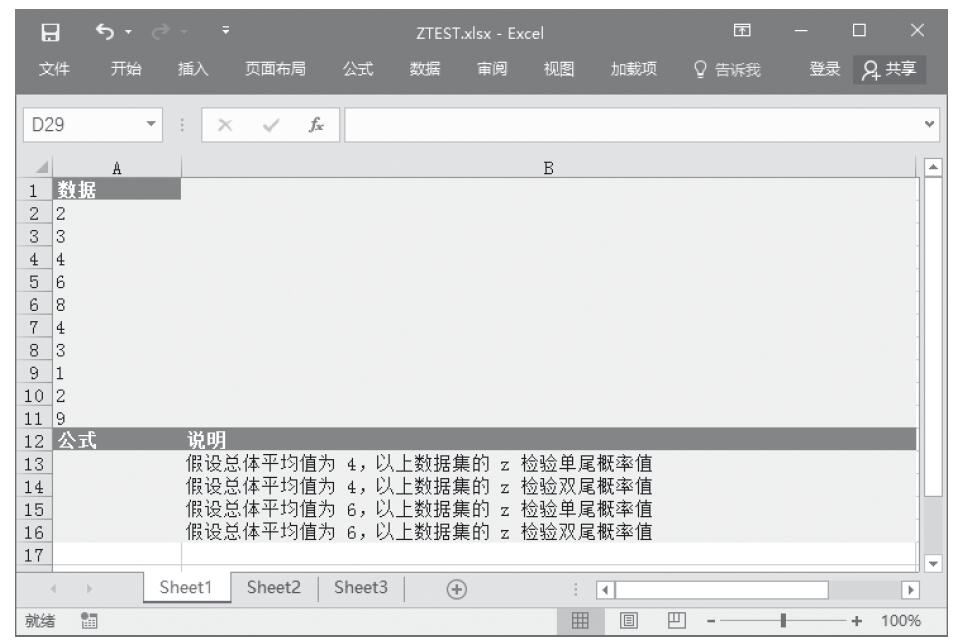
图16-45 基础数据
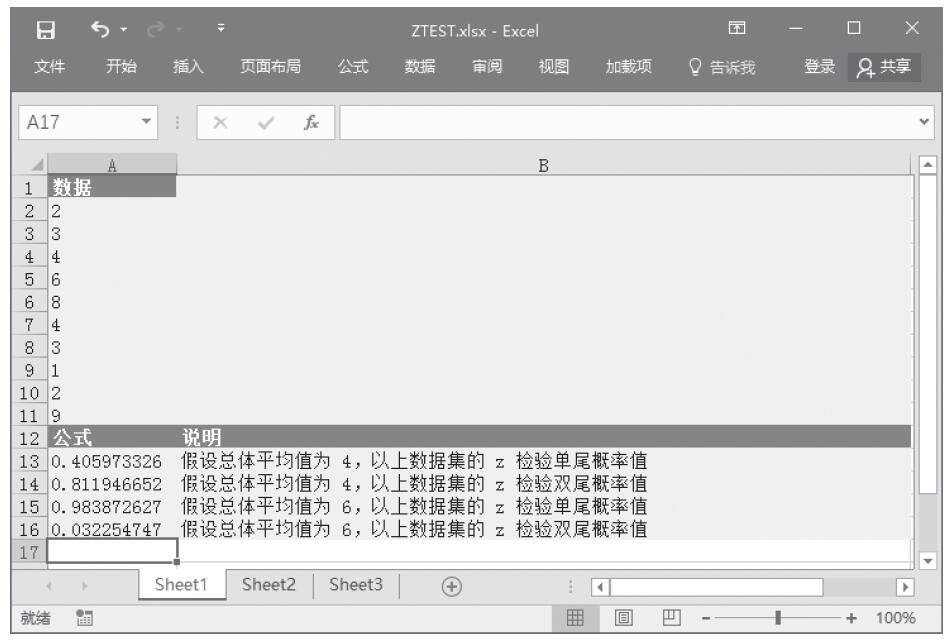
图16-46 计算结果
【使用指南】如果array为空,函数ZTEST返回错误值“#N/A”。不省略sigma时,函数ZTEST的计算公式如下:

省略sigma时,函数ZTEST的计算公式如下:

其中,x为样本平均值AVERAGE(array);s为样本标准偏差STDEV(array);n为样本中的观察值个数COUNT(array)。
ZTEST表示当基础总体平均值为μ0时,样本平均值大于观察值AVERAGE(array)的概率。由于正态分布是对称的,如果AVERAGE(array)<μ0,则ZTEST的返回值将大于0.5。
当基础总体平均值为μ0,样本平均值从μ0(沿任一方向)变化到AVERAGE(array)时,下面的Excel公式可用于计算双尾概率。
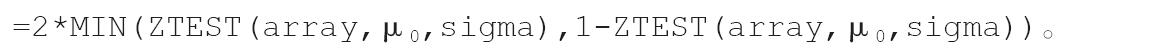
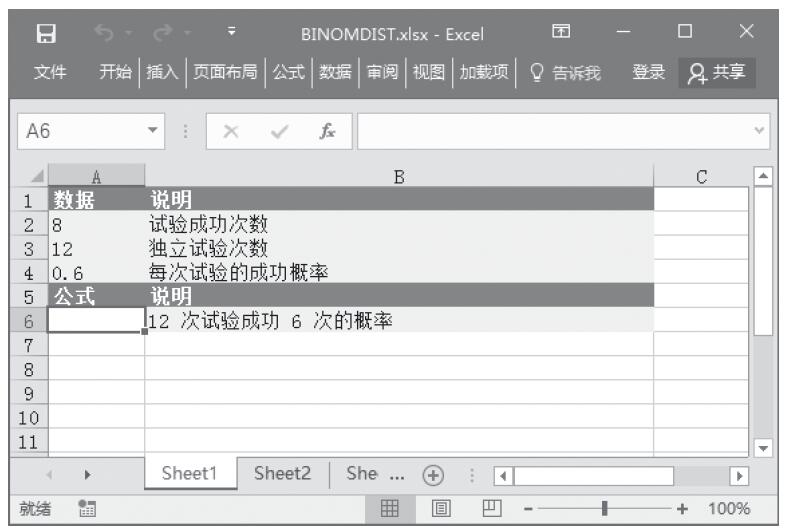
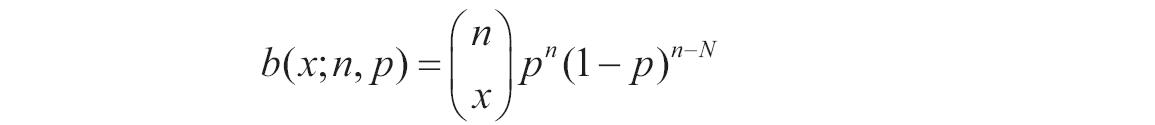
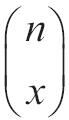 等于COMBIN(n,x)。
等于COMBIN(n,x)。