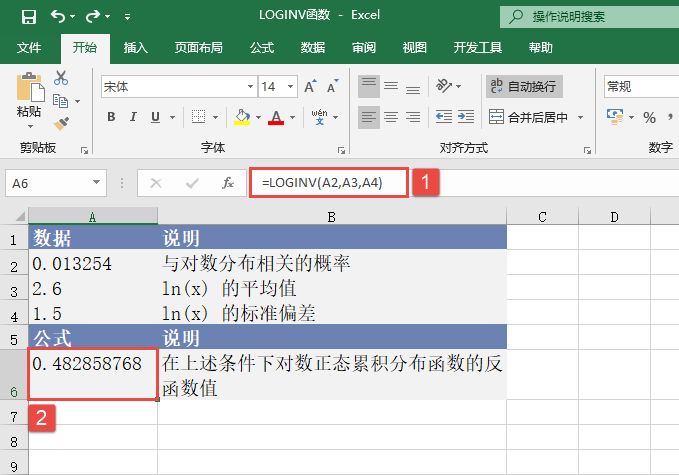
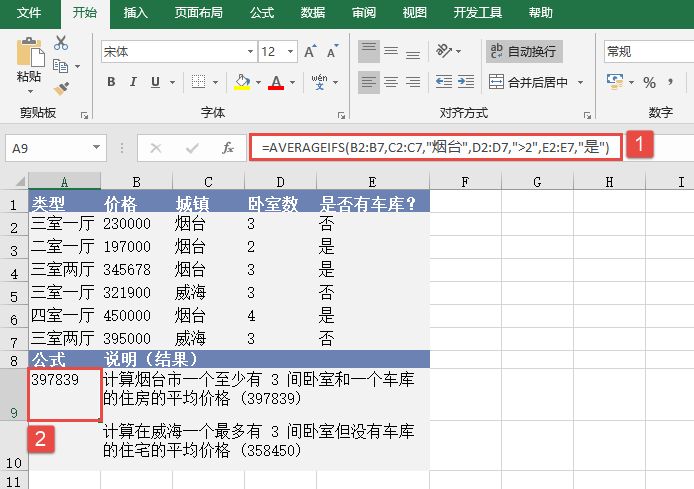
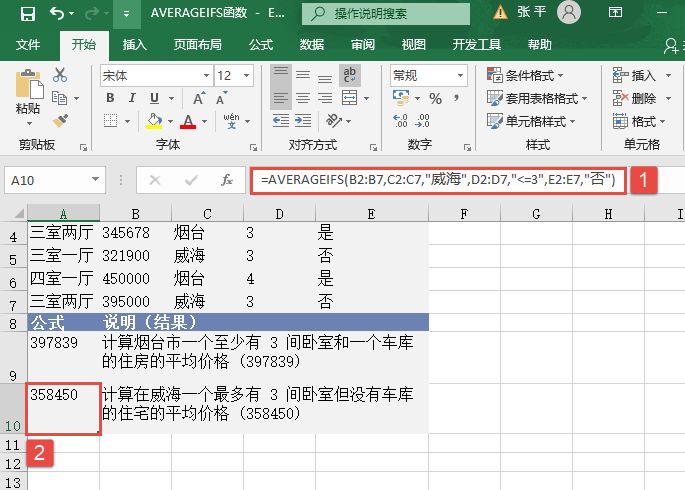
MEDIAN函数用于计算给定数值的中值。中值是在一组数值中居于中间的数值。MEDIAN函数的语法如下:
MEDIAN(number1,number2,...)
其中,参数number1、number2……是要计算中值的1~255个数字。
MEDIAN函数用于计算趋中性,趋中性是统计分布中一组数中间的位置。3种最常见的趋中性计算方法如下。
- 平均值:平均值是算术平均数,由一组数相加然后除以这些数的个数计算得出。例如,2、3、3、5、7和10的平均数是30除以6,结果是5。
- 中值:中值是一组数中间位置的数;即一半数的值比中值大,另一半数的值比中值小。例如,2、3、3、5、7和10的中值是4。
- 众数:众数是一组数中最常出现的数。例如,2、3、3、5、7和10的众数是3。
对于对称分布的一组数来说,这3种趋中性计算方法是相同的。对于偏态分布的一组数来说,这3种趋中性计算方法可能不同。下面通过实例详细讲解该函数的使用方法与技巧。
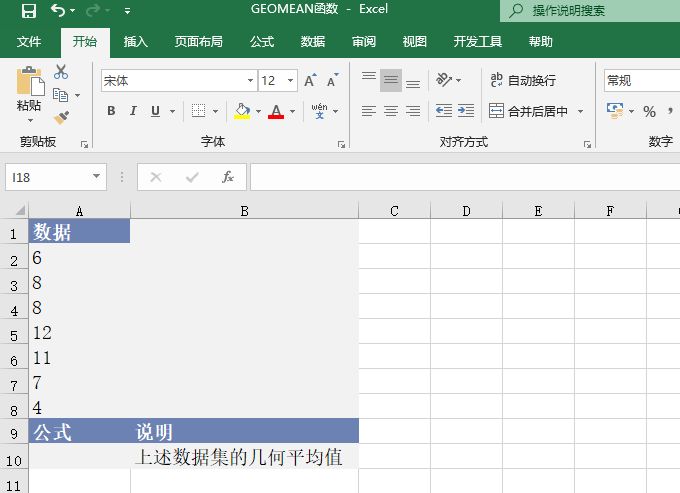
打开“MEDIAN函数.xlsx”工作簿,切换至“Sheet1”工作表,本例中的原始数据如图18-31所示。工作表中已经给定了一组数据,需按要求计算出数据列表中的中值。具体操作步骤如下。
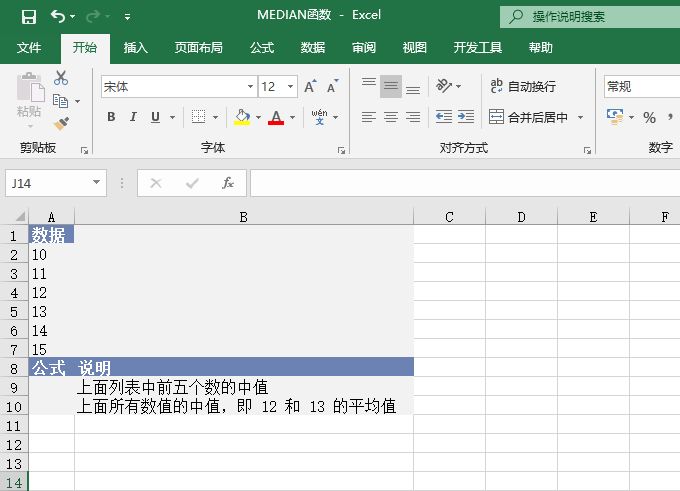
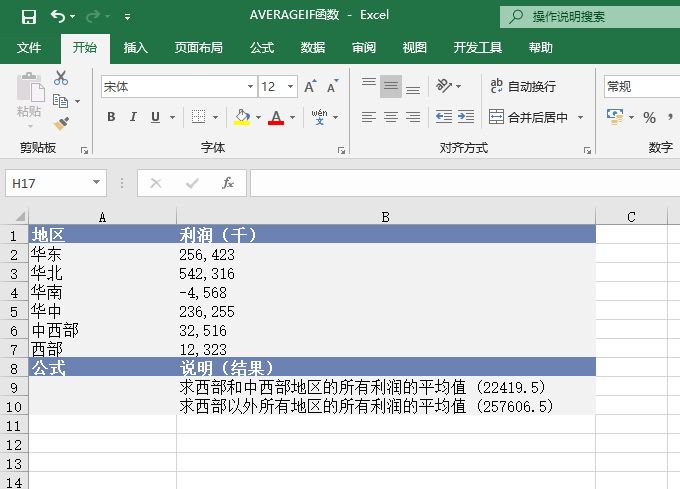
图18-31 原始数据
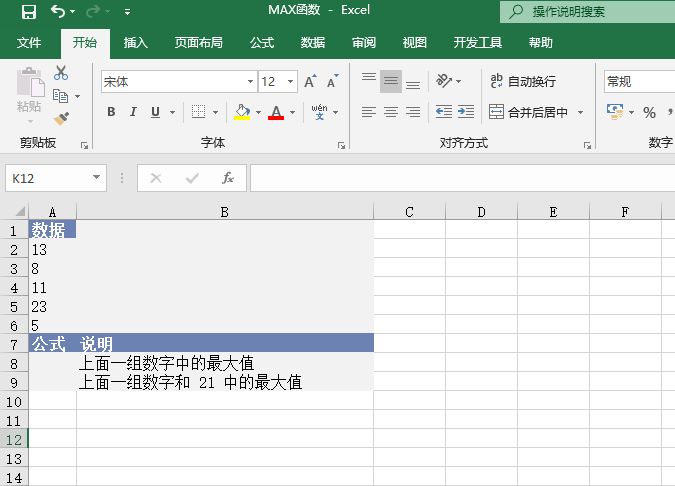
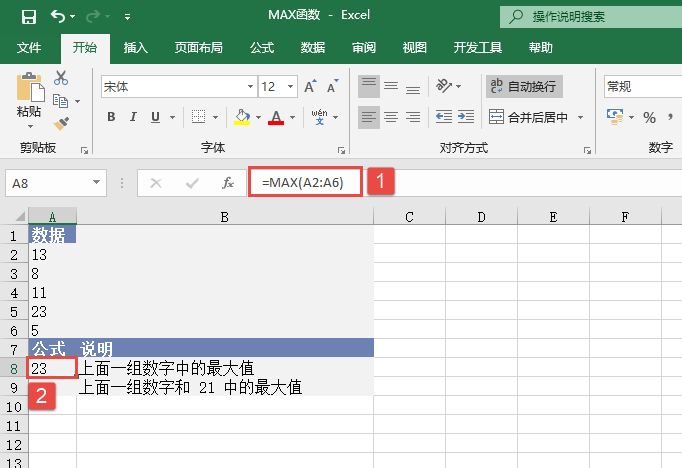
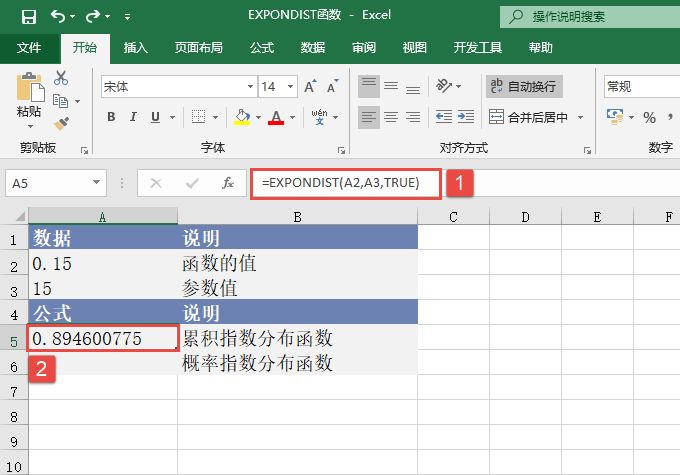
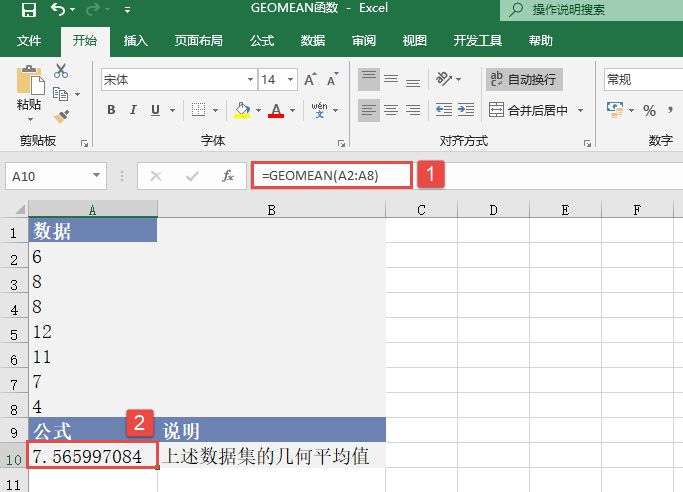
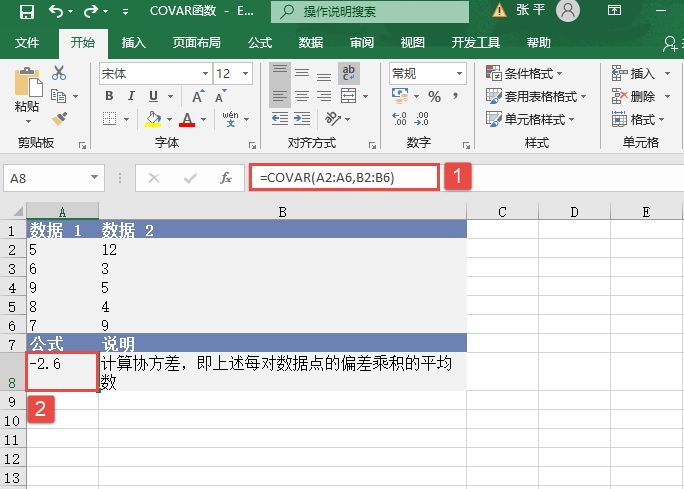
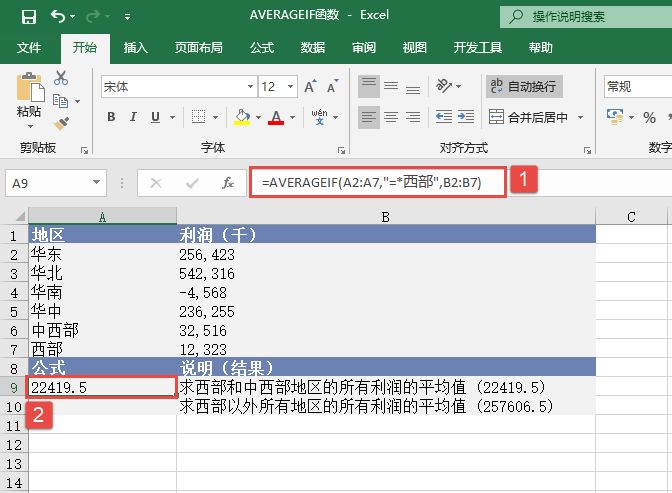
STEP01:选中A9单元格,在编辑栏中输入公式“=MEDIAN(A2:A6)”,用于计算上面列表中前5个数的中值,输入完成后按“Enter”键返回计算结果,如图18-32所示。
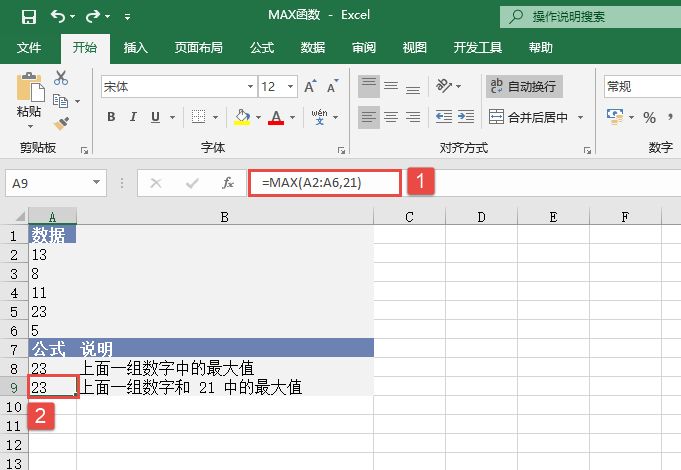
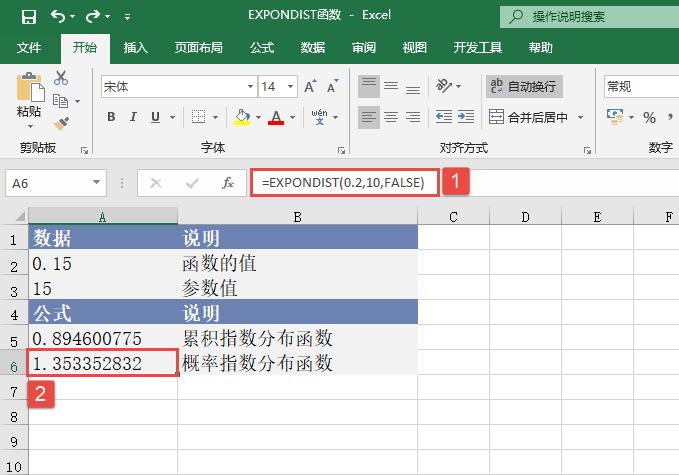
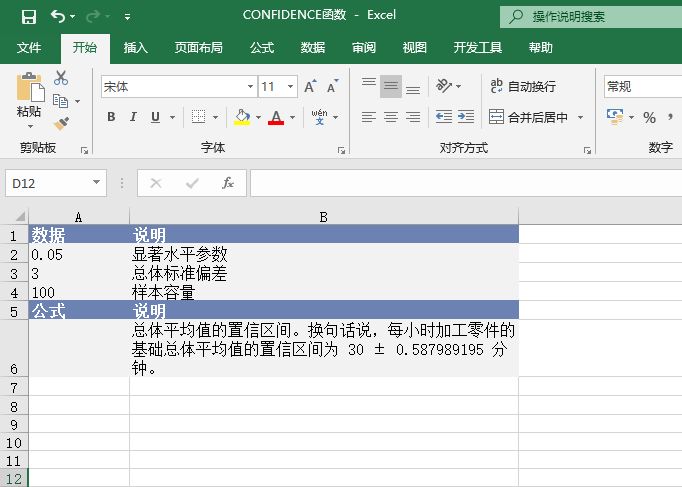
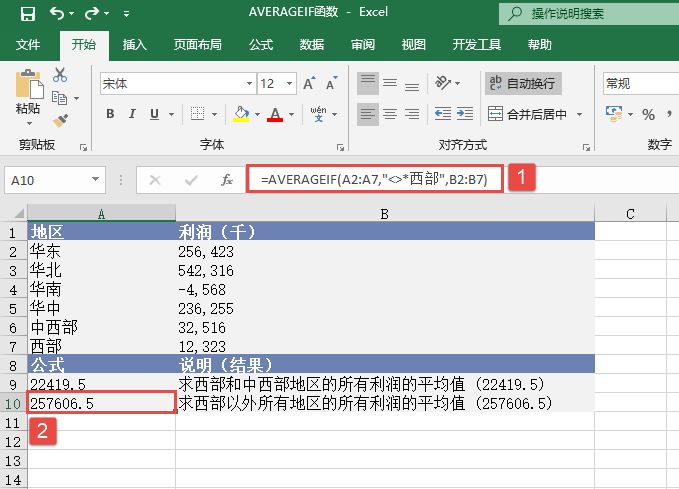
STEP02:选中A10单元格,在编辑栏中输入公式“=MEDIAN(A2:A7)”,用于计算上面所有数值的中值,输入完成后按“Enter”键返回计算结果,如图18-33所示。
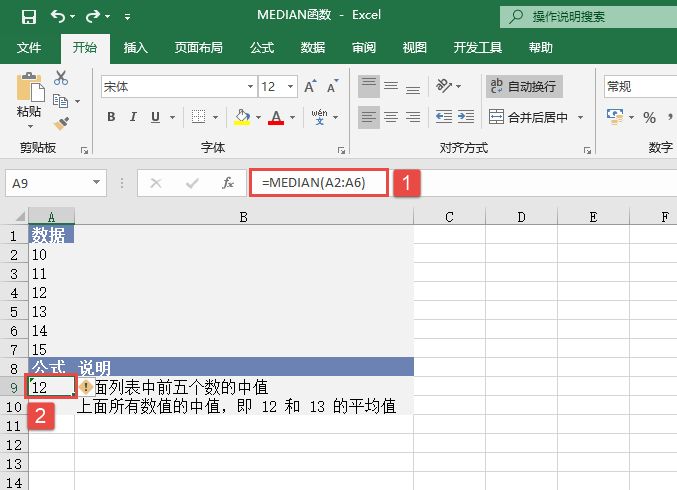
图18-32 计算中值
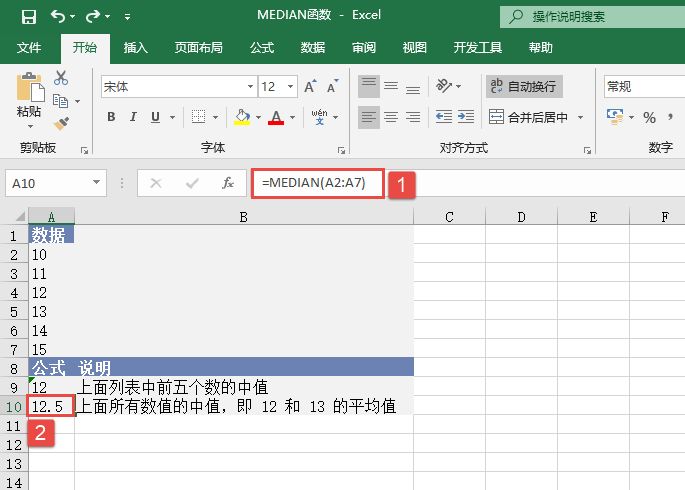
图18-33 计算所有数值的中值
如果参数集合中包含偶数个数字,函数MEDIAN将返回位于中间的两个数的平均值。参数可以是数字或者是包含数字的名称、数组或引用。逻辑值和直接键入参数列表中代表数字的文本被计算在内。如果数组或引用参数包含文本、逻辑值或空白单元格,则这些值将被忽略;但包含零值的单元格将计算在内。如果参数为错误值或为不能转换为数字的文本,将会导致错误。