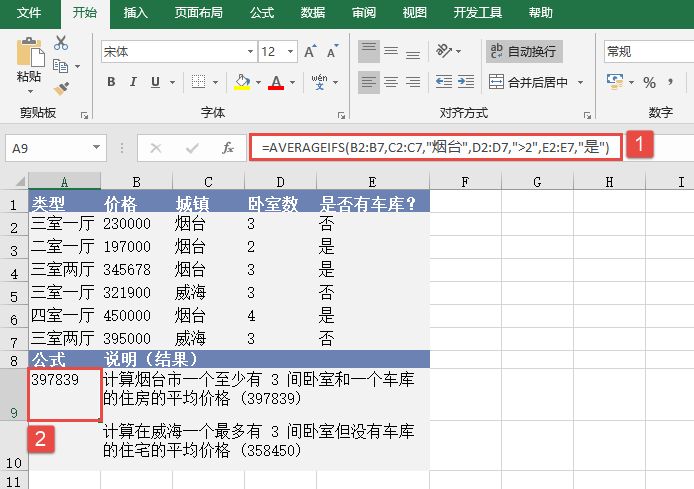
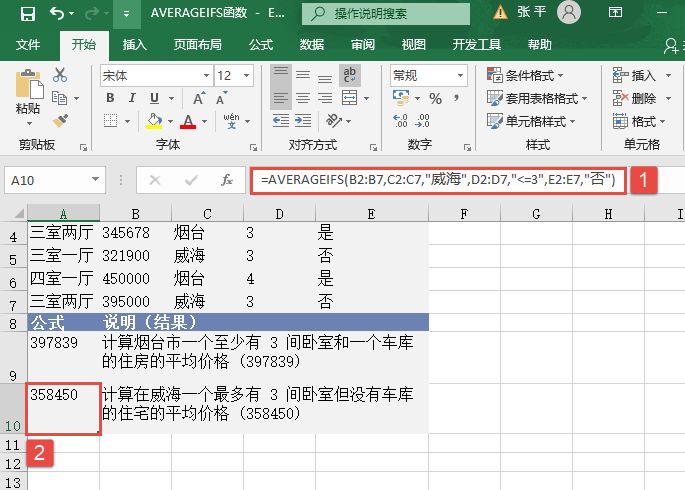
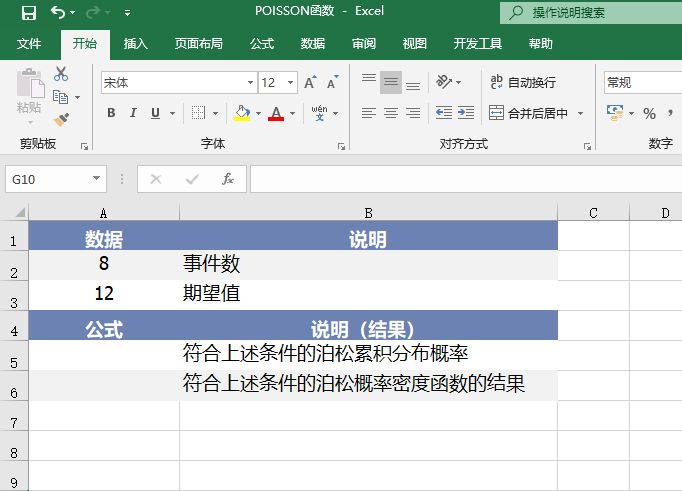
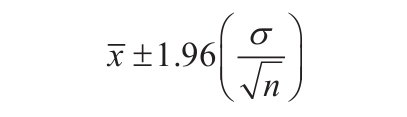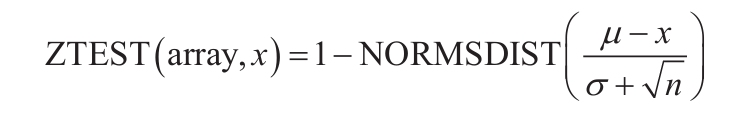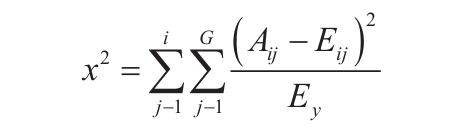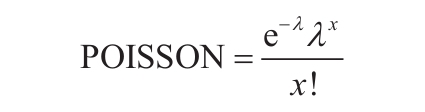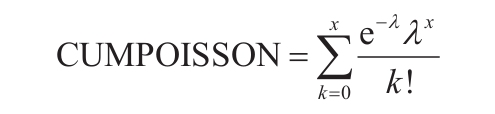CONFIDENCE函数返回一个值,可以使用该值构建总体平均值的置信区间。CONFIDENCE函数的语法如下:
CONFIDENCE(alpha,standard_dev,size)
其中,alpha参数是用于计算置信度的显著水平参数。置信度等于100*(1-alpha)%,也就是说,如果alpha参数为0.05,则置信度为95%。standard_dev参数为数据区域的总体标准偏差,假设为已知。size参数为样本容量。
置信区间是一个值区域。样本平均值x位于该区域的中间,区域范围为x±CONFIDENCE。例如,如果通过邮购的方式订购产品,其交付时间的样本平均值为x,则总体平均值的区域范围为x±CONFIDENCE。对于任何包含在本区域中的总体平均值μ0,从μ0到x,获取样本平均值的概率大于alpha;对于任何未包含在本区域中的总体平均值μ0,从μ0到x,获取样本平均值的概率小于alpha。换句话说,假设使用x、standard_dev和size构建一个双尾检验,假设的显著性水平为alpha,总体平均值为μ0。如果μ0包含在置信区间中,则不能拒绝该假设;如果μ0未包含在置信区间中,则将拒绝该假设。置信区间不允许进行概率为1–alpha的推断,此时下一份邮购包裹的交付时间将肯定位于置信区间内。下面通过实例详细讲解该函数的使用方法与技巧。
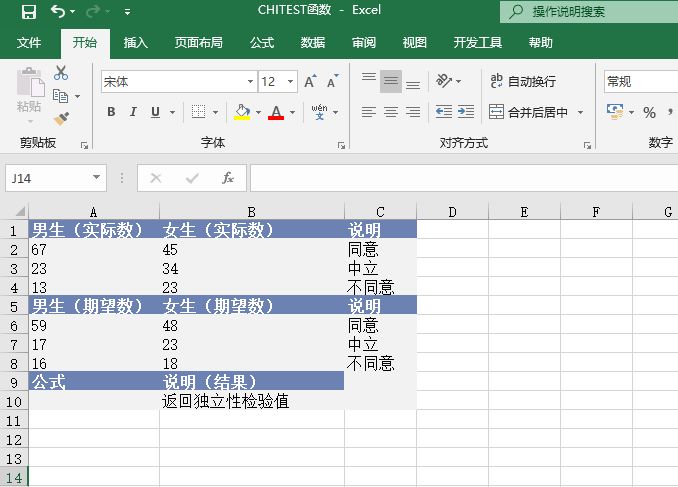
打开“CONFIDENCE函数.xlsx”工作簿,切换至“Sheet1”工作表,本例中的原始数据如图18-14所示。假设样本取自100名某生产车间的工人,他们平均每小时加工的零件数量为30个,总体标准偏差为3个,假设alpha=0.05。具体操作步骤如下。
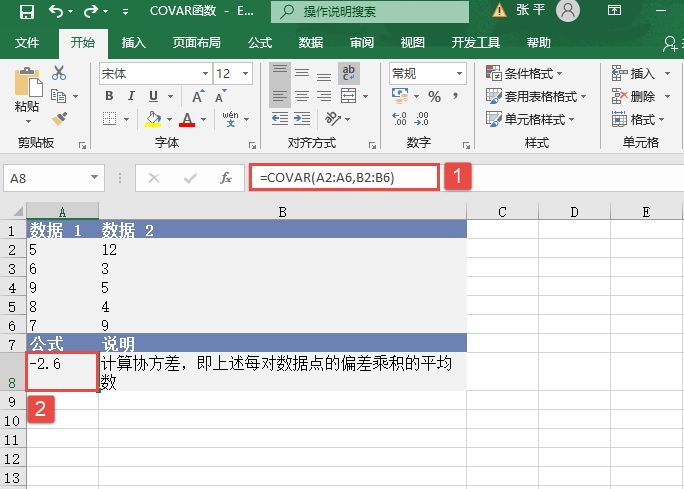
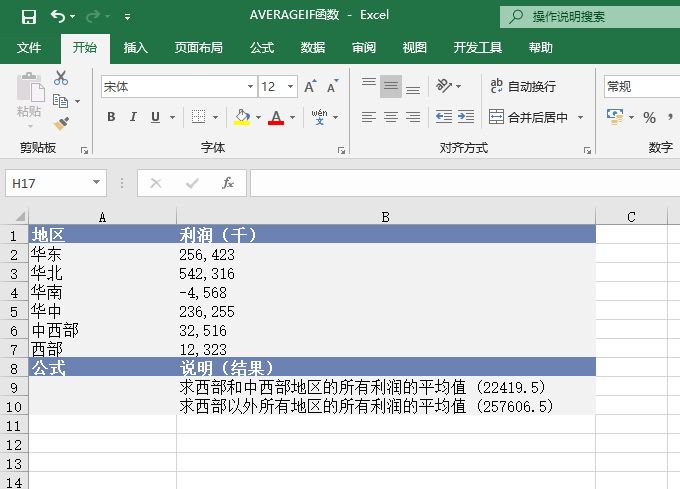
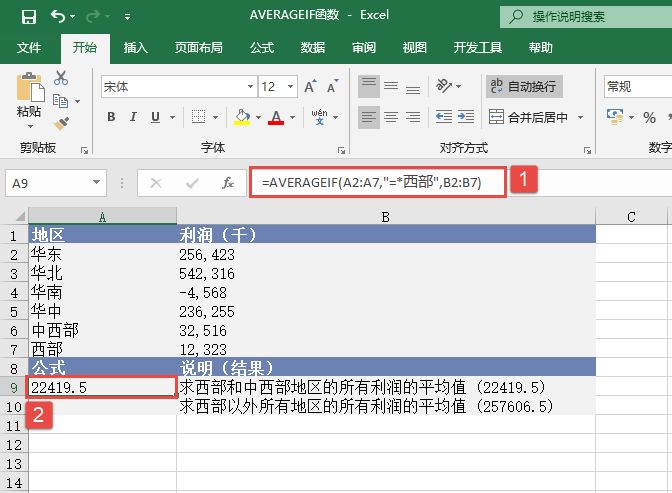
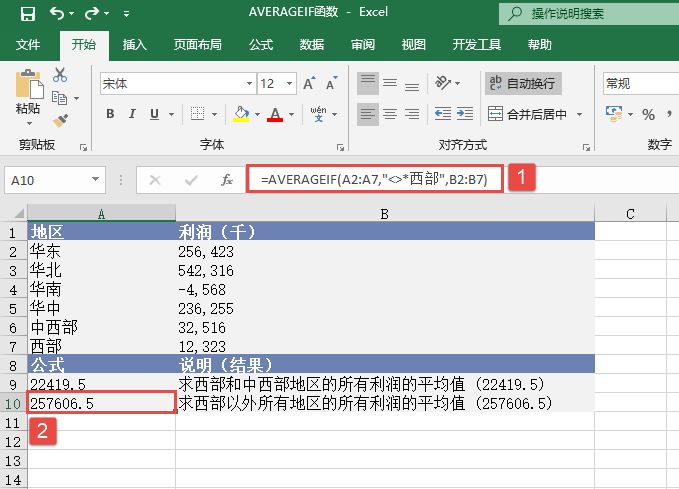
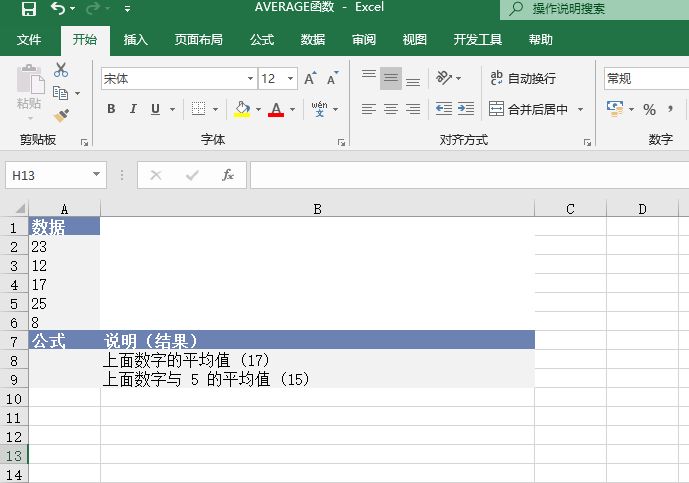
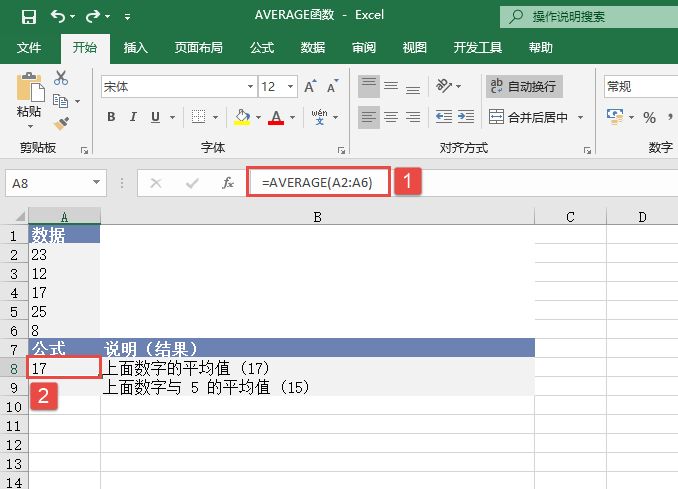
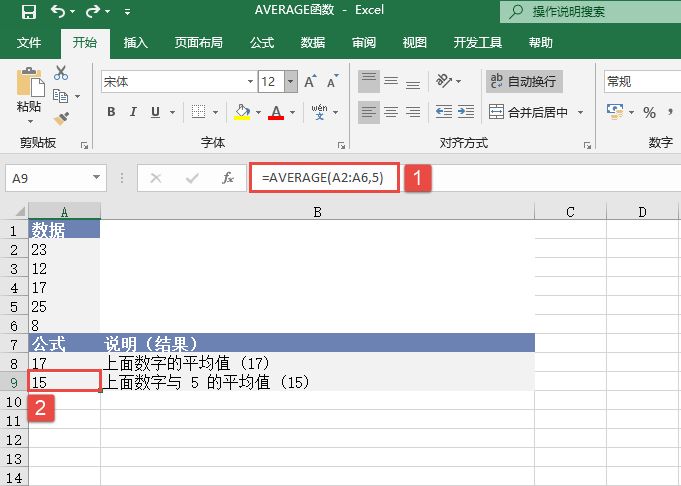
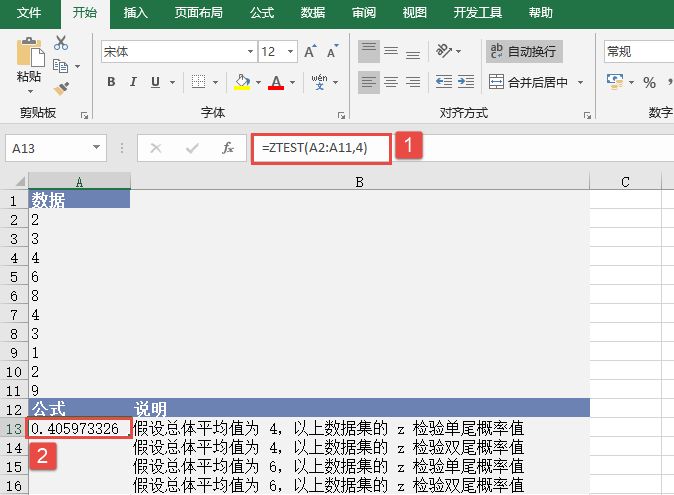
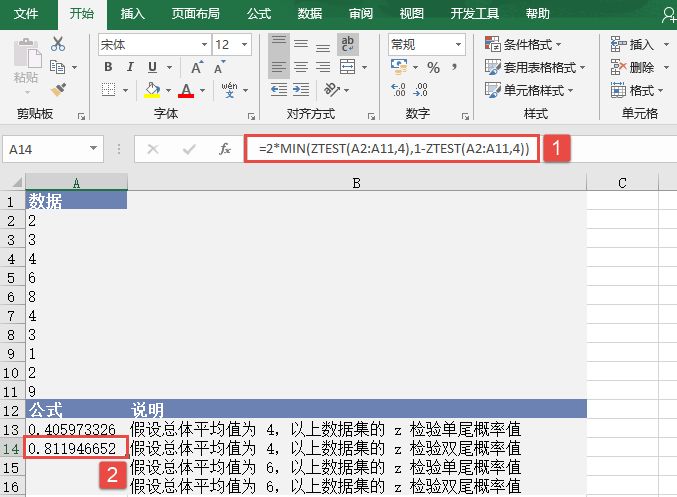
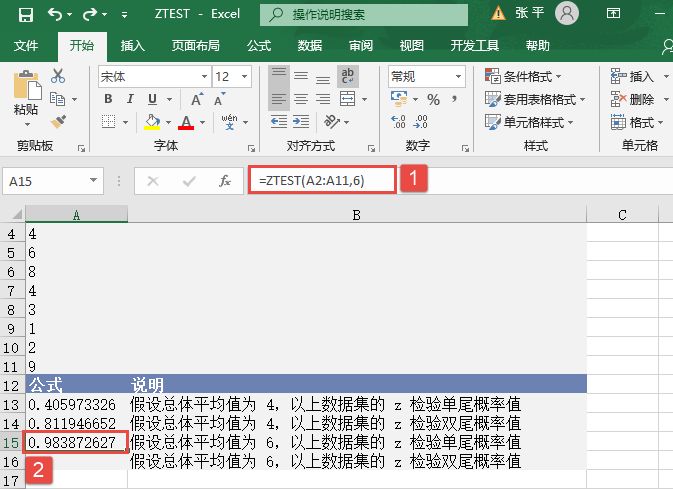
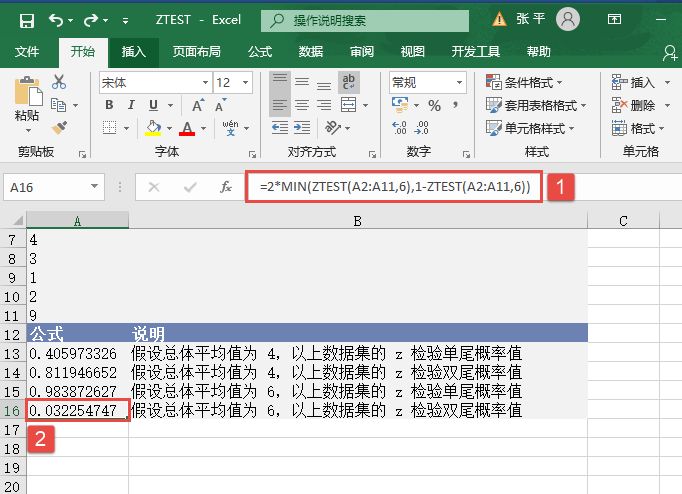
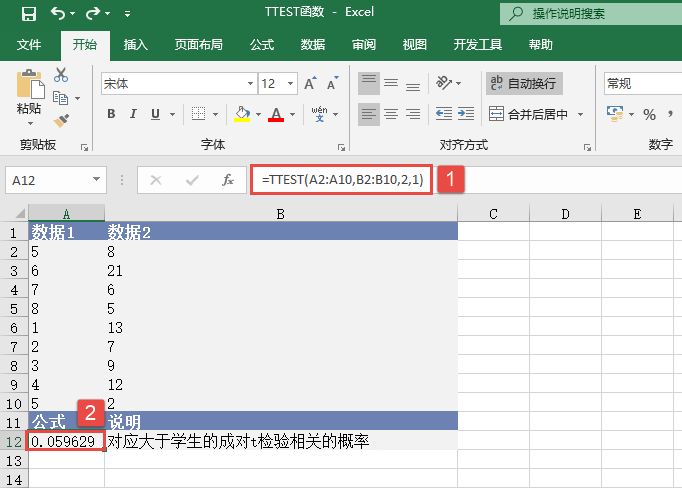
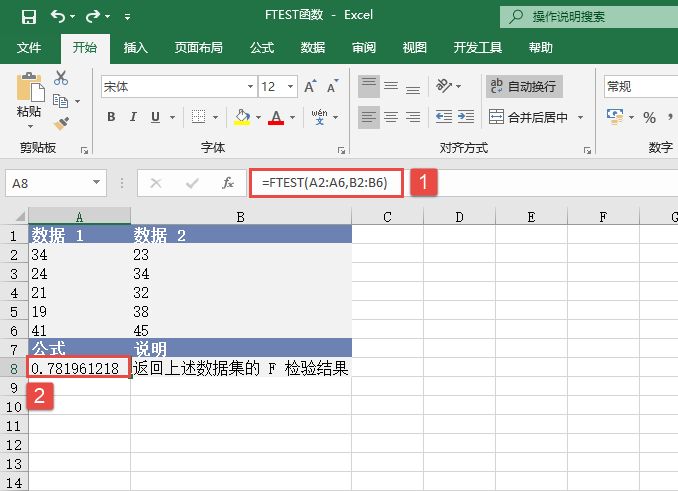
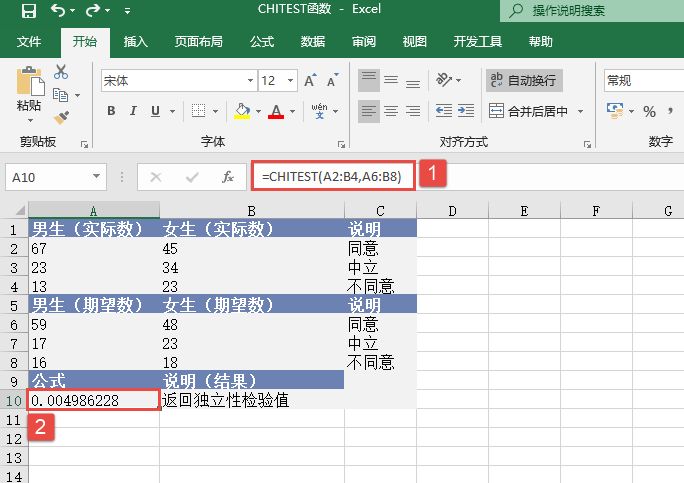
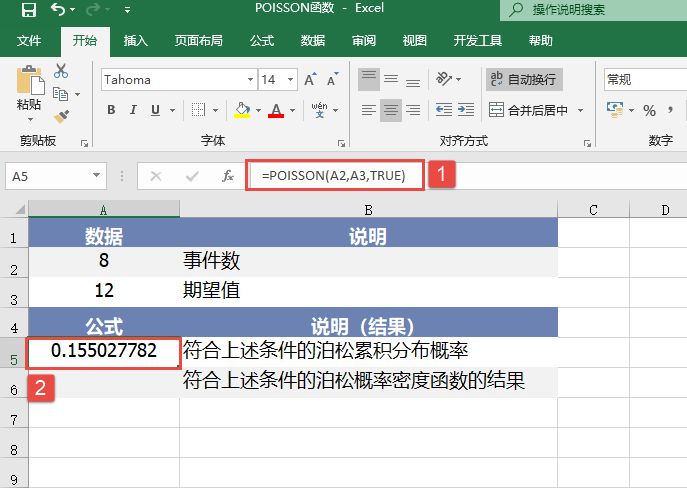
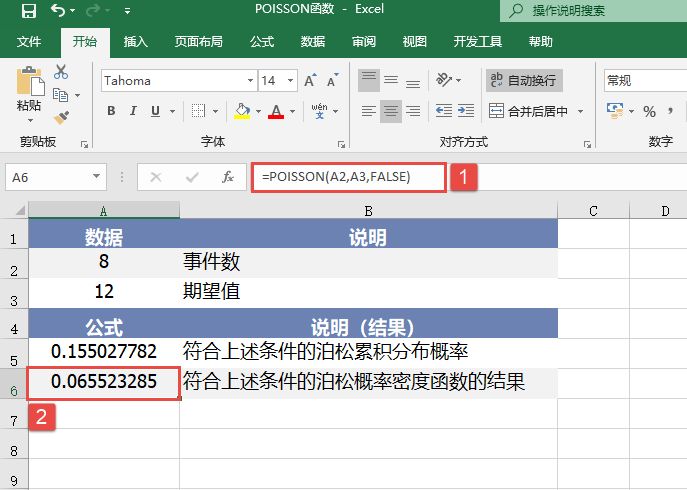
选中A6单元格,在编辑栏中输入公式“=CONFIDENCE(0.05,3,100)”,用于计算总体平均值的置信区间,输入完成后按“Enter”键返回计算结果,如图18-15所示。
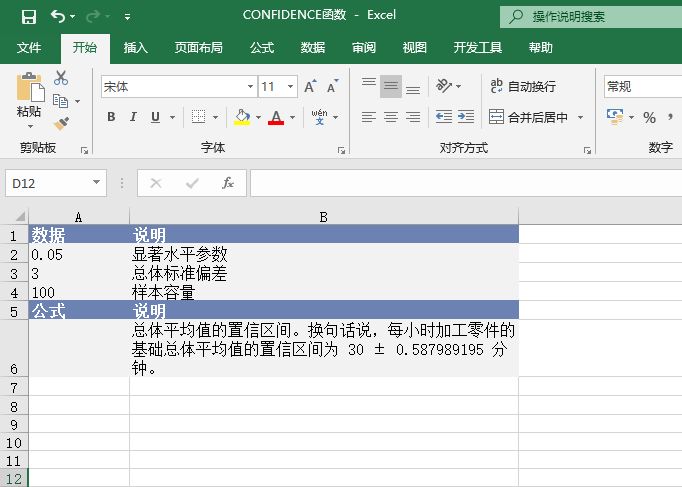
图18-14 原始数据
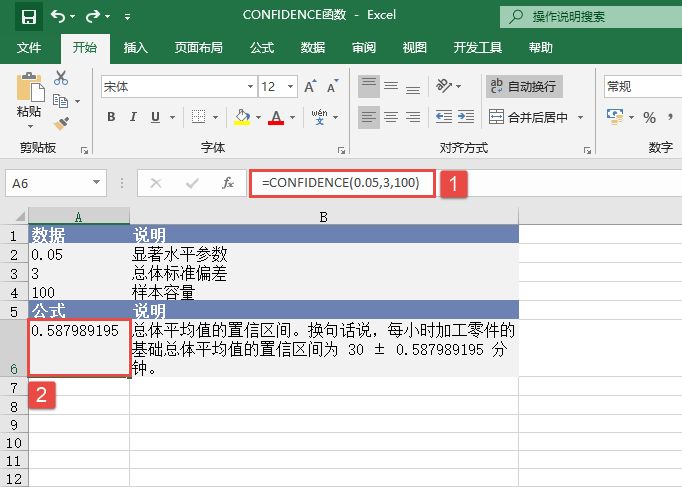
图18-15 计算置信区间
如果任意参数为非数值型,函数CONFIDENCE返回错误值“#VALUE!”。如果参数alpha≤0或alpha≥1,函数CONFIDENCE返回错误值“#NUM!”。如参数果standard_dev≤0,函数CONFIDENCE返回错误值“#NUM!”。如果size参数不是整数,将被截尾取整。如果参数size<1,函数CONFIDENCE返回错误值“#NUM!”。假设alpha参数等于0.05,则需要计算等于(1-alpha)或95%的标准正态分布曲线之下的面积。其面积值为±1.96。因此置信区间为: