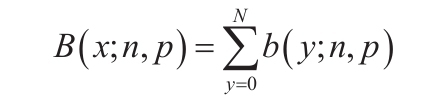POISSON函数用于返回泊松分布。泊松分布通常用于预测一段时间内事件发生的次数,比如一分钟内通过收费站的轿车的数量。POISSON函数的语法如下:
POISSON(x,mean,cumulative)
其中,x参数为事件数,mean参数为期望值,cumulative参数为一逻辑值,确定所返回的概率分布形式。如果cumulative为TRUE,函数POISSON返回泊松累积分布概率,即,随机事件发生的次数在0到x之间(包含0和1);如果为FALSE,则返回泊松概率密度函数,即随机事件发生的次数恰好为x。下面通过实例详细讲解该函数的使用方法与技巧。
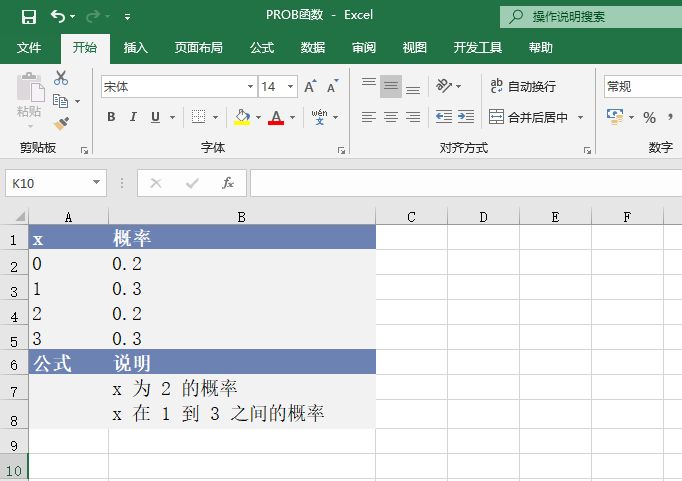
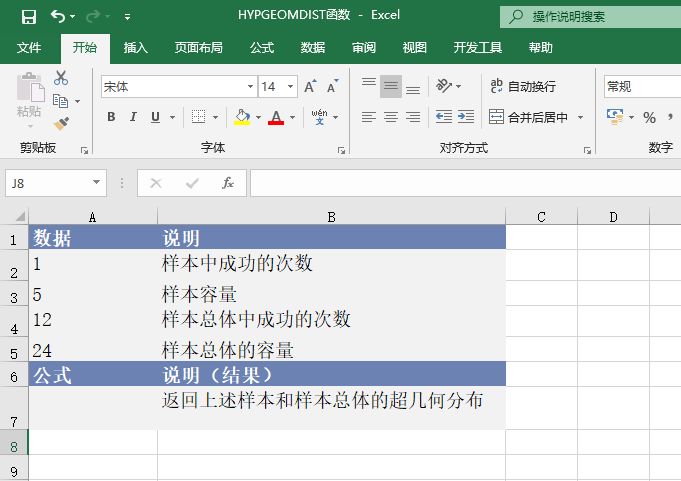
打开“POISSON函数.xlsx”工作簿,切换至“Sheet1”工作表,本例中的原始数据如图17-16所示。已知事件数和期望值,要求计算符合这些条件的泊松累积分布概率和泊松概率密度函数的结果。具体的操作步骤如下。
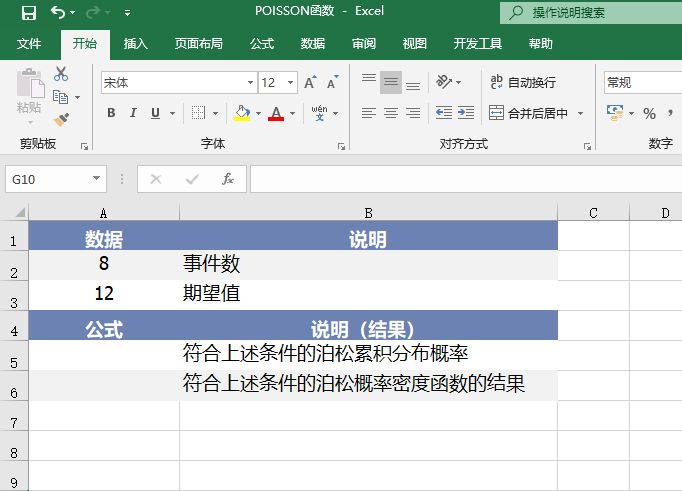
图17-16 原始数据
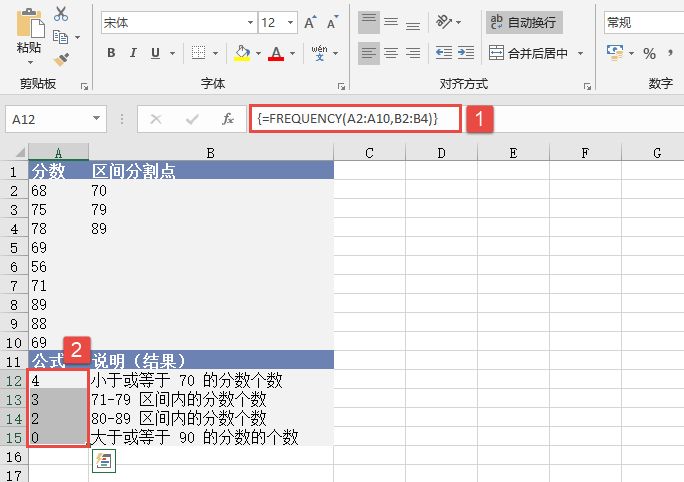
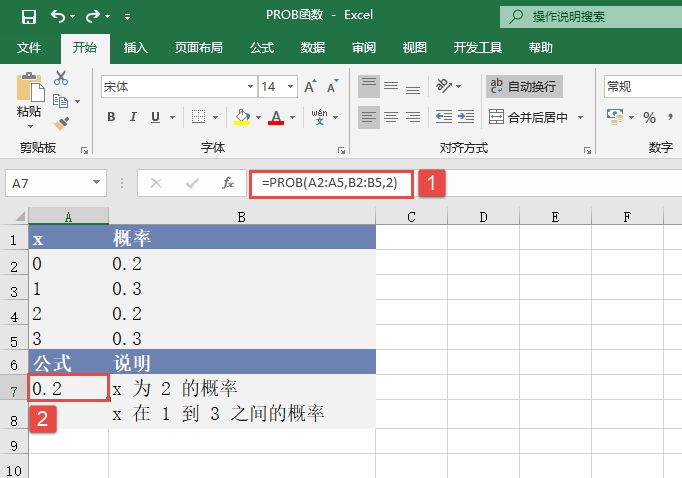
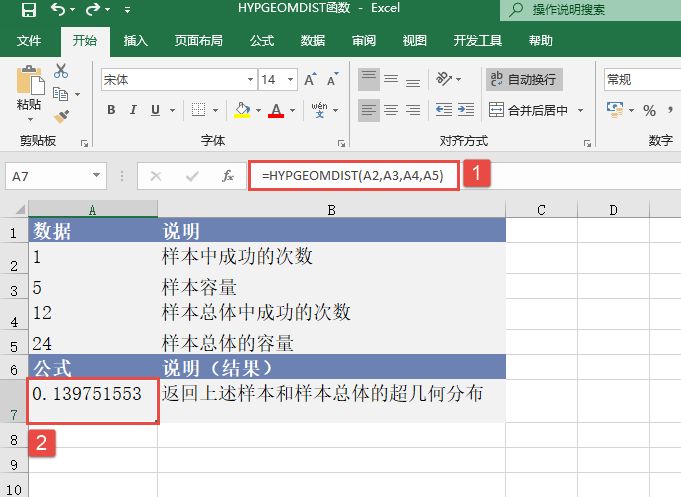
STEP01:选中A5单元格,在编辑栏中输入公式“=POISSON(A2,A3,TRUE)”,用于计算符合上述条件的泊松累积分布概率,输入完成后按“Enter”键返回计算结果,如图17-17所示。
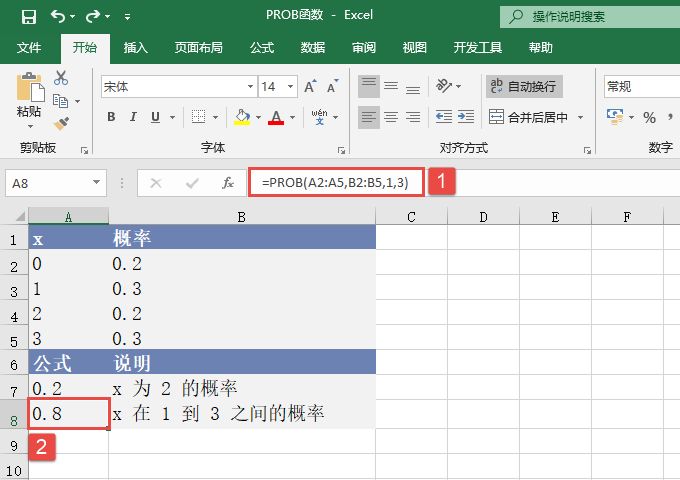
STEP02:选中A6单元格,在编辑栏中输入公式“=POISSON(A2,A3,FALSE)”,用于计算符合上述条件的泊松概率密度函数的结果,输入完成后按“Enter”键返回计算结果,如图17-18所示。
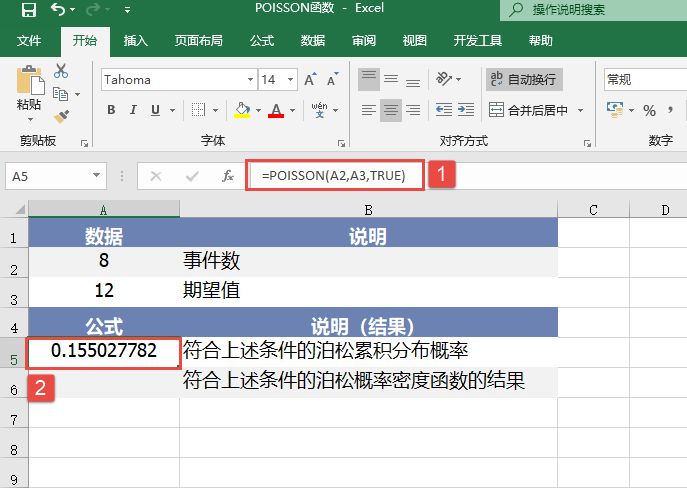
图17-17 计算符合上述条件的泊松累积分布概率
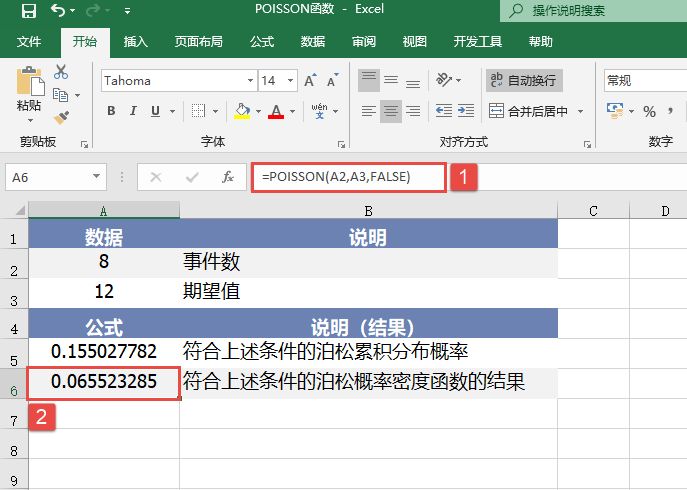
图17-18 计算泊松概率密度函数的结果
如果x参数不为整数,将被截尾取整。如果x参数或mean参数为非数值型,函数POISSON返回错误值“#VALUE!”。如果参数x<0,函数POISSON返回错误值“#NUM!”。如果参数mean<0,函数POISSON返回错误值“#NUM!”。函数POISSON的计算公式如下:
假设cumulative=FALSE,
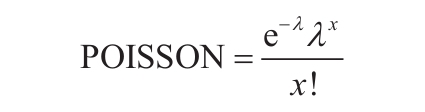
假设cumulative=TRUE,
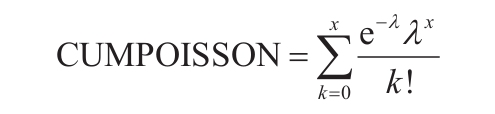
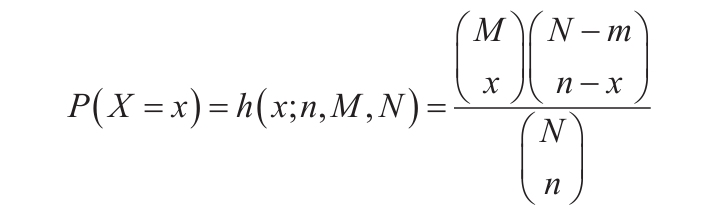
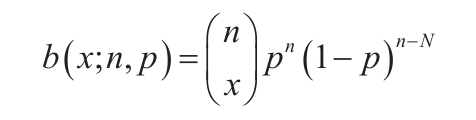
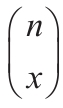 等于COMBIN(n,x)。
等于COMBIN(n,x)。