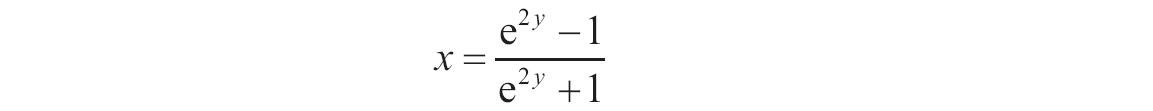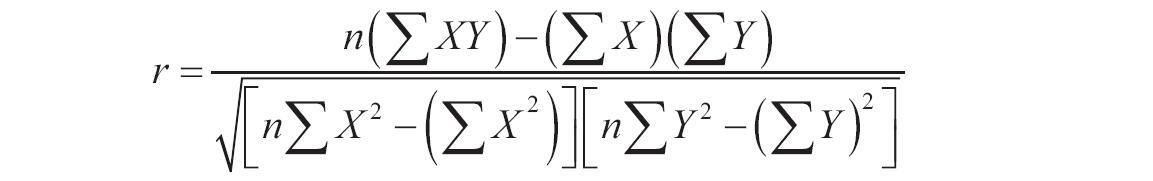GAMMADIST函数用于计算γ分布。可以使用此函数来研究具有偏态分布的变量。γ分布通常用于排队分析。GAMMADIST函数的语法如下。
GAMMADIST(x,alpha,beta,cumulative)
其中参数x为用来计算分布的数值,alpha为分布参数,beta为分布参数。如果beta=1,函数GAMMADIST返回标准γ分布。cumulative为一逻辑值,决定函数的形式。如果cumulative为TRUE,函数GAMMADIST返回累积分布函数;如果为FALSE,则返回概率密度函数。
典型案例
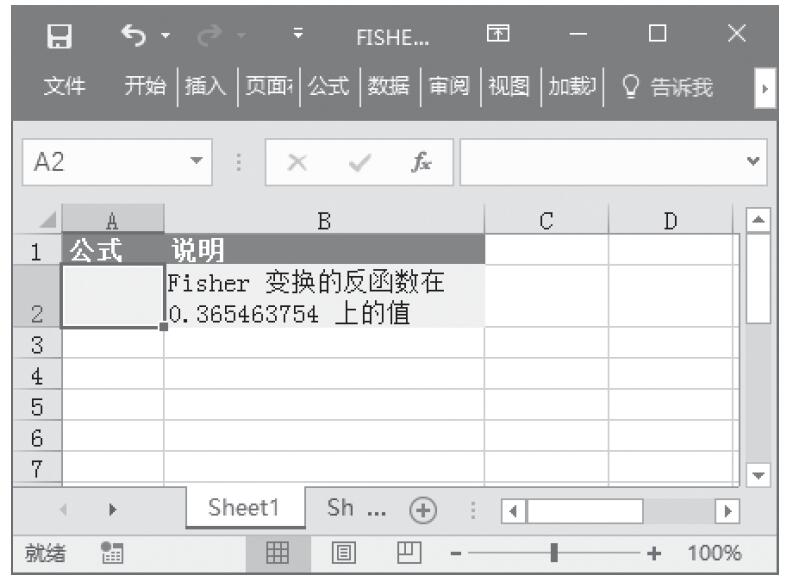
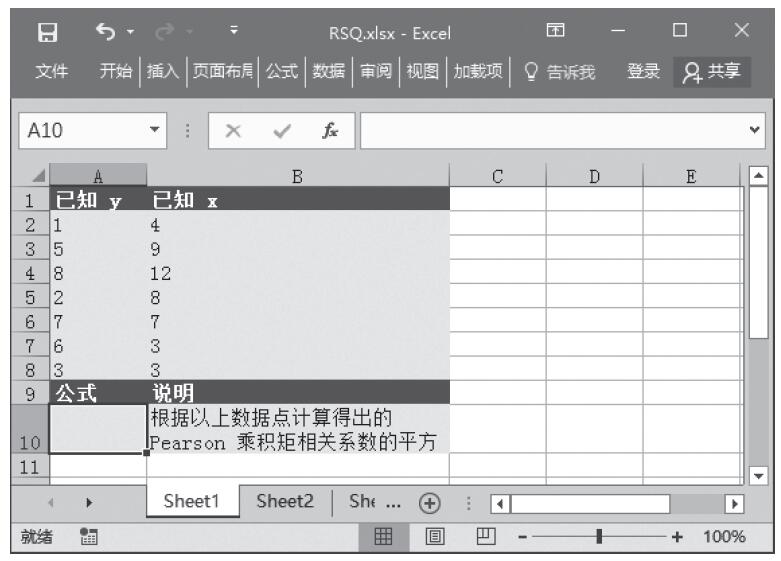
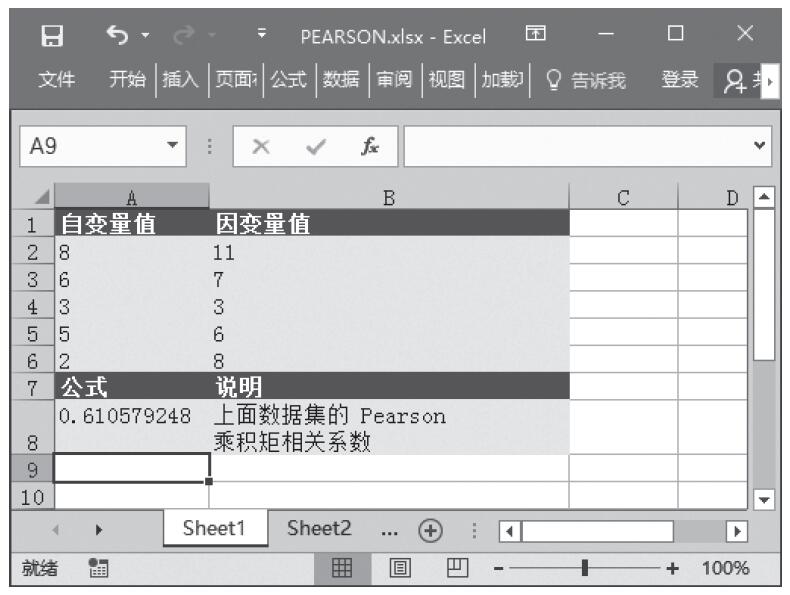
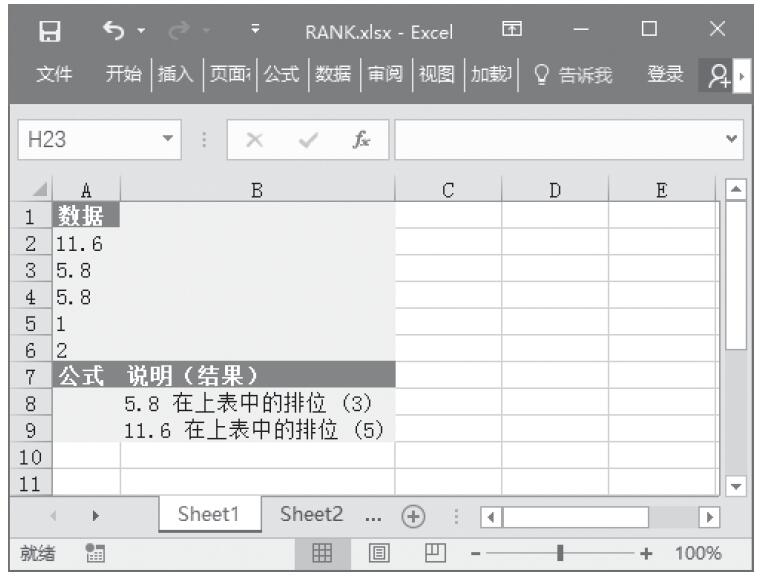
已知用来计算分布的数值、Alpha分布参数、Beta分布参数,计算这些条件下的概率γ分布和累积γ分布。基础数据如图16-147所示。
步骤1:打开例子工作簿“GAMMADIST.xlsx”。
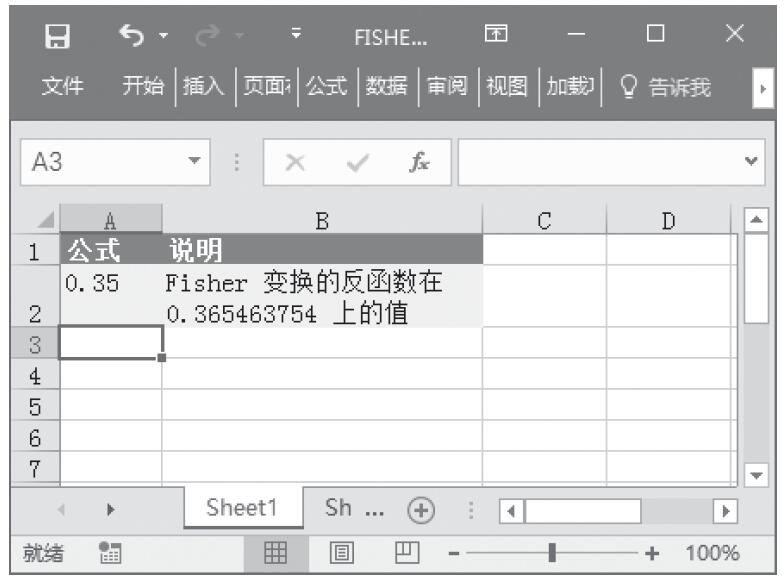
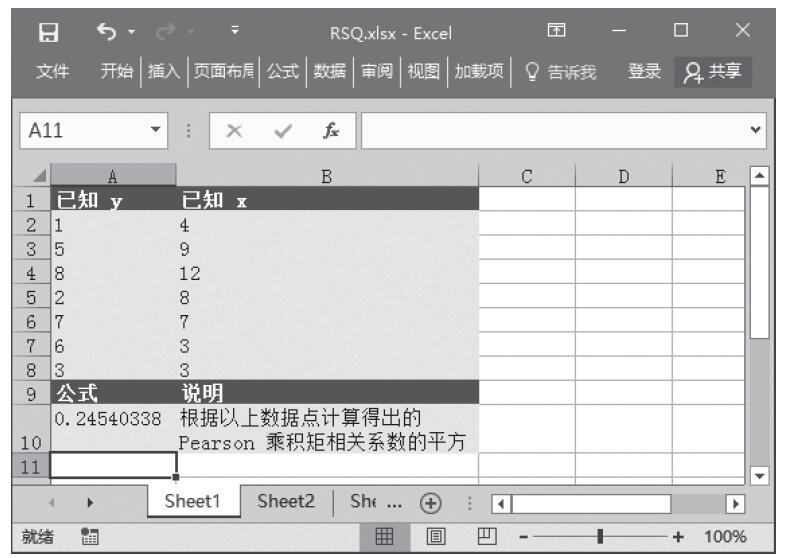
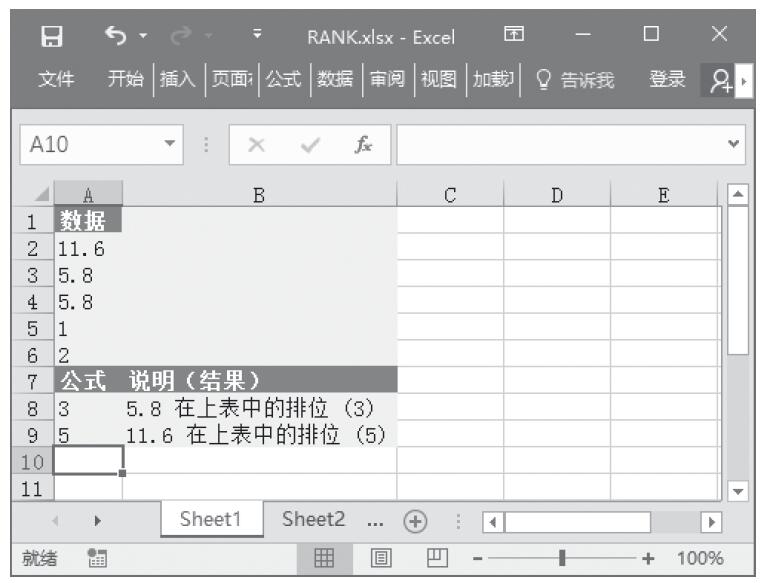
步骤2:在单元格A6中输入公式“=GAMMADIST(A2,A3,A4,FALSE)”,用于计算在上述条件下的概率γ分布。
步骤3:在单元格A7中输入公式“=GAMMADIST(A2,A3,A4,TRUE)”,用于计算在上述条件下的累积γ分布。计算结果如图16-148所示。
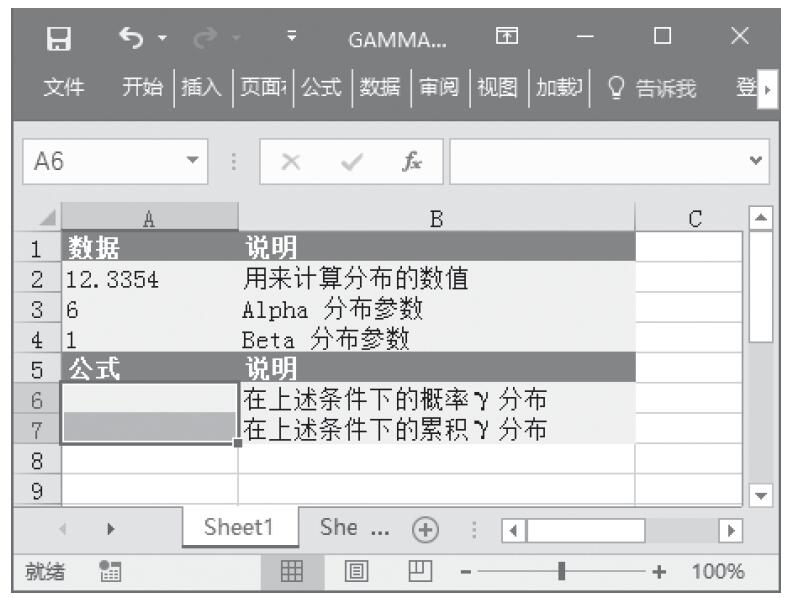
图16-147 基础数据
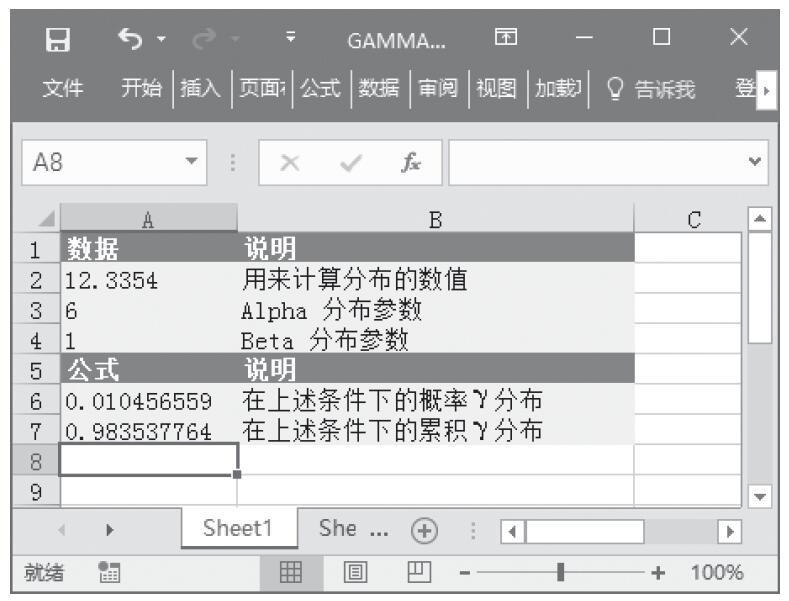
图16-148 计算结果
使用指南
如果x、alpha或beta为非数值型,函数GAMMADIST返回错误值“#VALUE!”;如果x<0,函数GAMMADIST返回错误值“#NUM!”;如果alpha≤0或beta≤0,函数GAMMADIST返回错误值“#NUM!”。γ概率密度函数的计算公式如下。
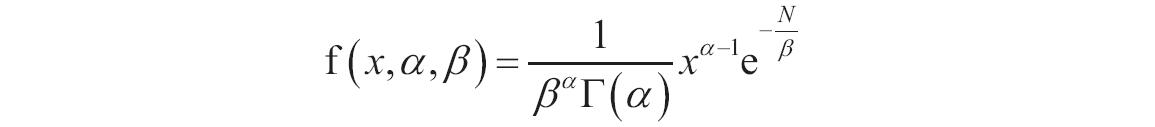
标准γ概率密度函数如下。
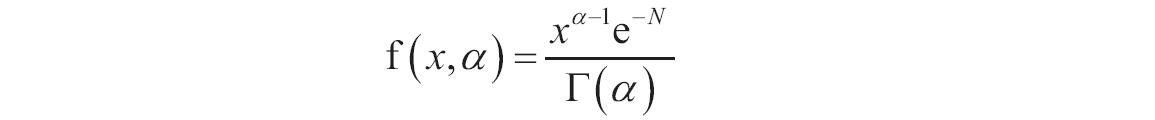
当alpha=1时,函数GAMMADIST返回如下的指数分布。
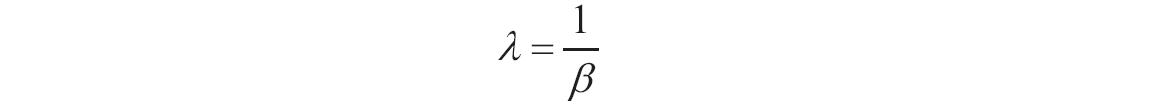
对于正整数n,当alpha=n/2,beta=2且cumulative=TRUE时,函数GAMMADIST以自由度n返回(1-CHIDIST(X))。当alpha为正整数时,函数GAMMADIST也称为爱尔朗(Erlang)分布。