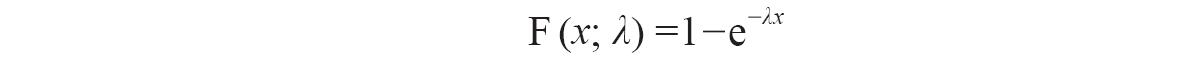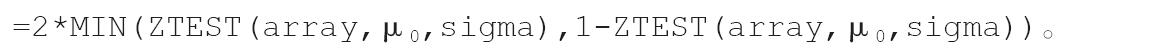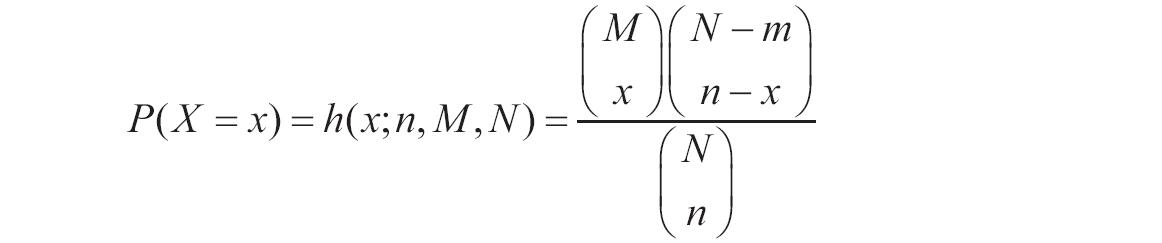EXPONDIST函数用于返回指数分布。使用函数EXPONDIST可以建立事件之间的时间间隔模型,例如,在计算银行自动提款机支付一次现金所花费的时间时,可通过函数EXPONDIST来确定这一过程最长持续一分钟的发生概率。EXPONDIST函数的语法如下。
EXPONDIST(x,lambda,cumulative)
其中参数x为函数的值。lambda为参数值。cumulative为一逻辑值,指定指数函数的形式。如果cumulative为TRUE,函数EXPONDIST返回累积分布函数;如果cumulative为FALSE,返回概率密度函数。
典型案例
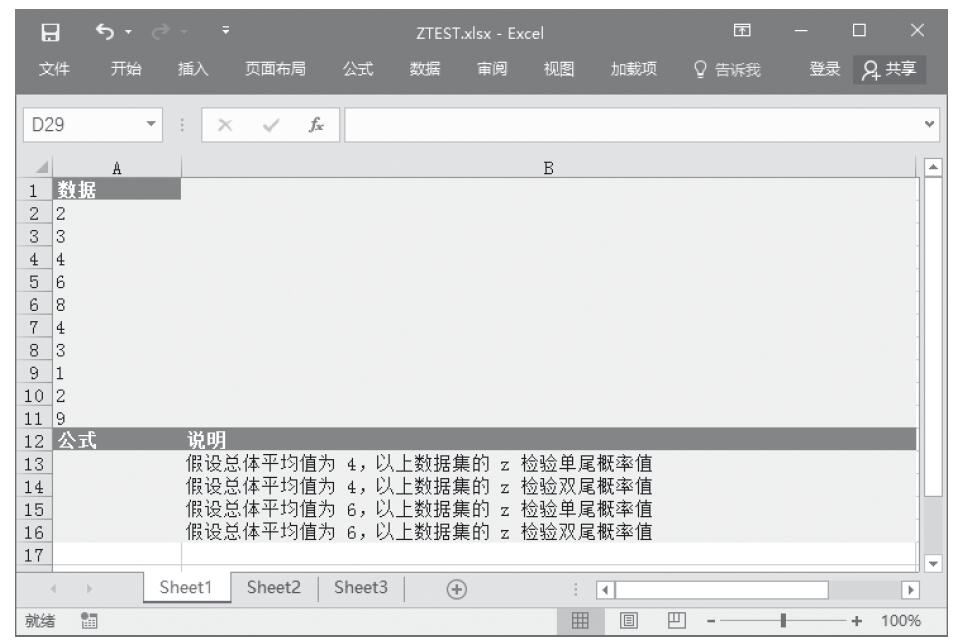
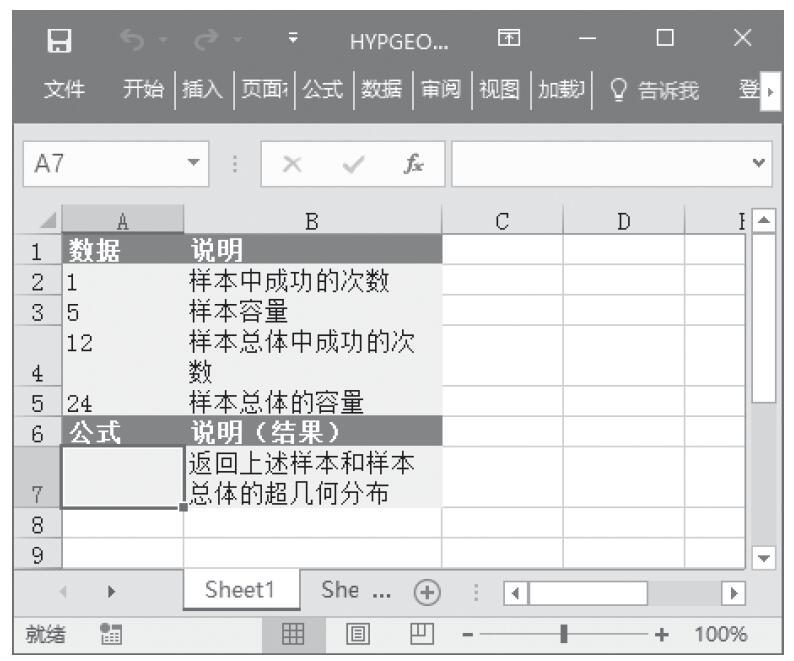
已知函数的值与参数值,试返回累积指数分布函数和概率指数分布函数。基础数据如图16-57所示。
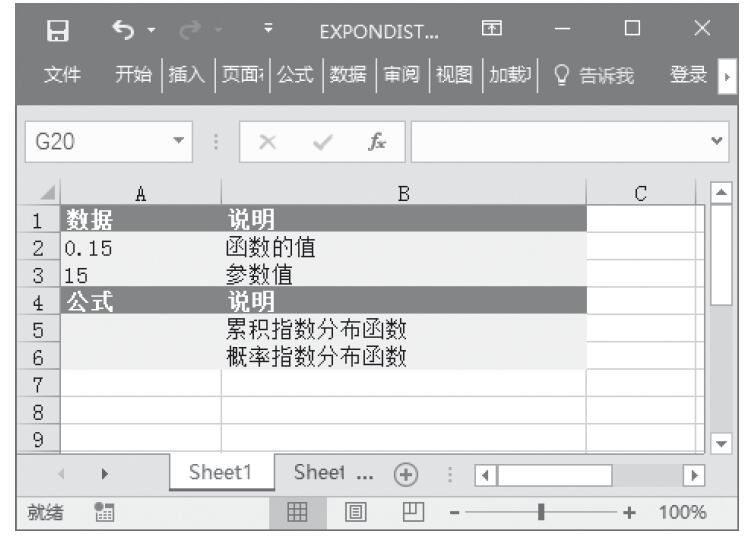
图16-57 基础数据
步骤1:打开例子工作簿“EXPONDIST.xlsx”。
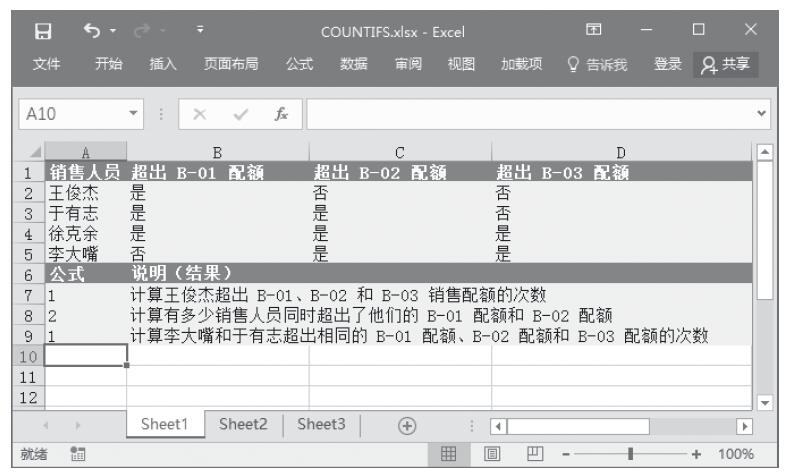
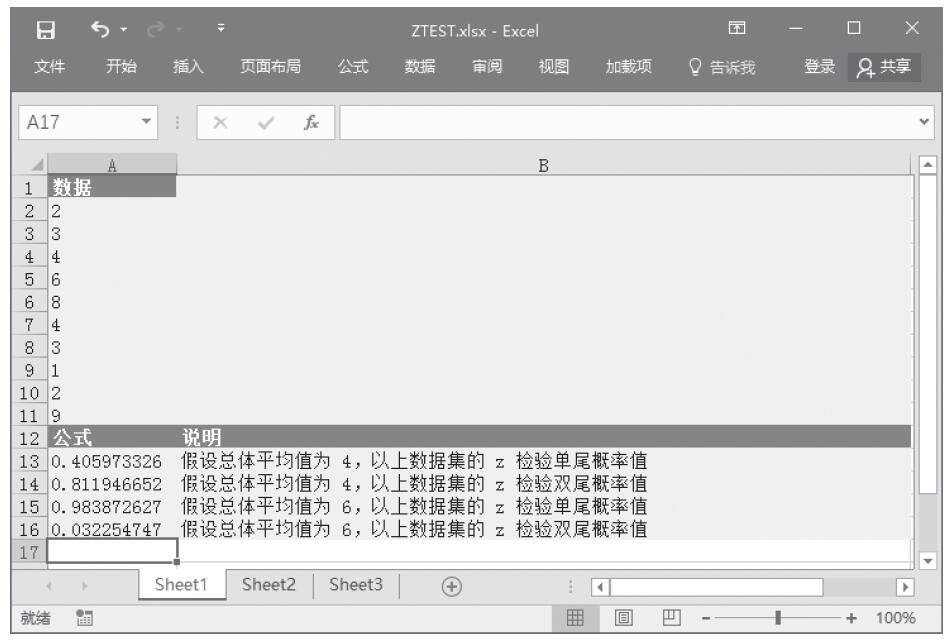
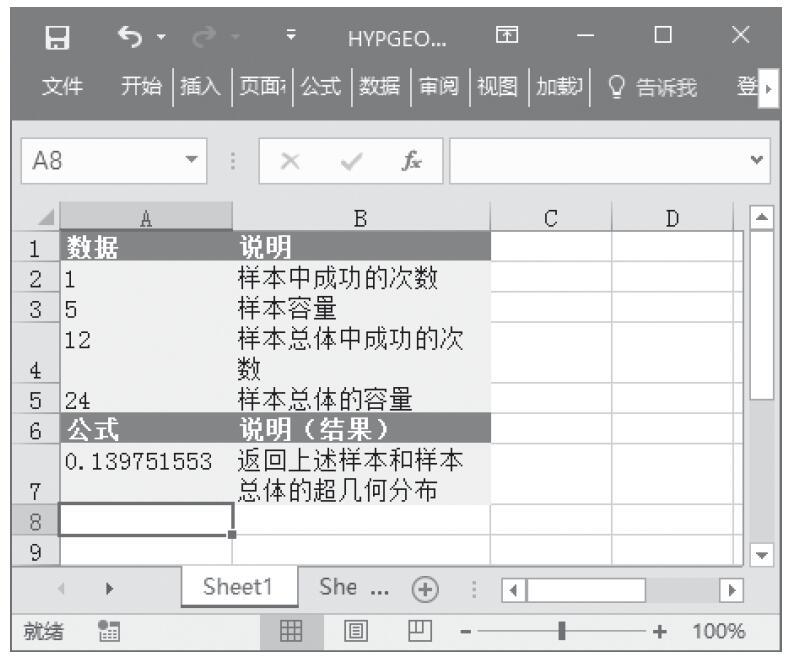
步骤2:在单元格A5中输入公式“=EXPONDIST(A2,A3,TRUE)”,用于返回累积指数分布函数。
步骤3:在单元格A6中输入公式“=EXPONDIST(0.2,10,FALSE)”,用于返回概率指数分布函数。计算结果如图16-58所示。
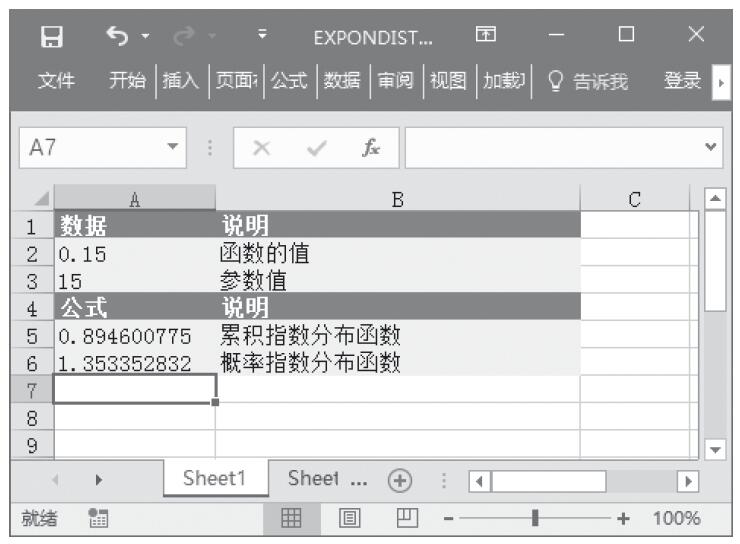
图16-58 计算结果
使用指南
如果x或lambda为非数值型,函数EXPONDIST返回错误值“#VALUE!”。如果x<0,函数EXPONDIST返回错误值“#NUM!”。如果lambda≤0,函数EXPONDIST返回错误值“#NUM!”。概率密度函数的计算公式为:
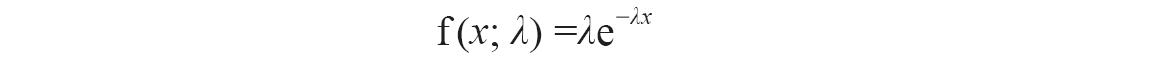
累积分布函数的计算公式为: