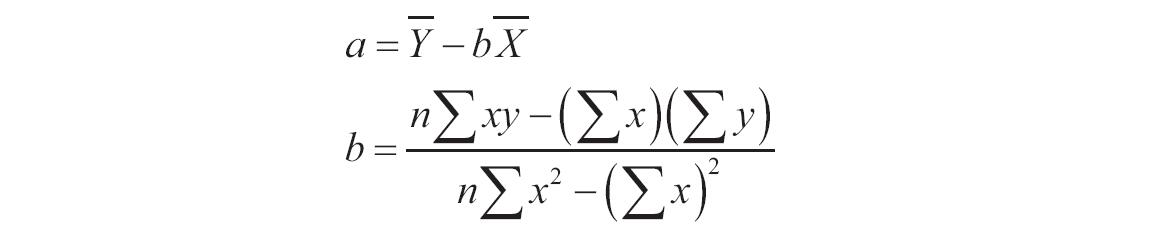TINV函数用于计算作为概率和自由度函数的学生t分布的t值。TINV函数的语法如下。
TINV(probability,degrees_freedom)
其中参数probability为对应于双尾学生t分布的概率,degrees_freedom为分布的自由度数值。
典型案例
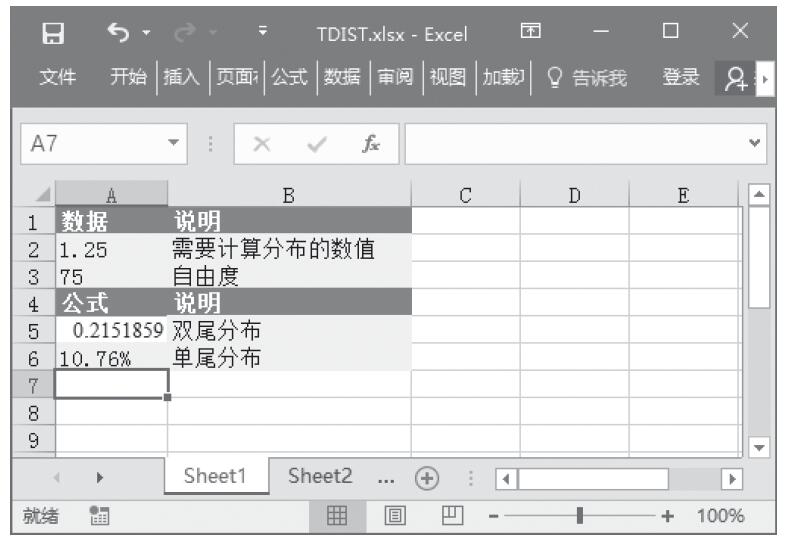
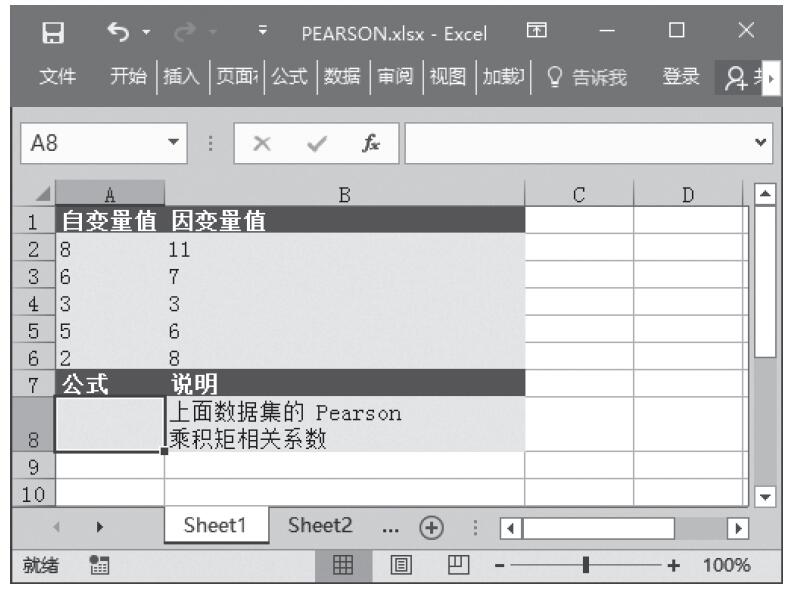
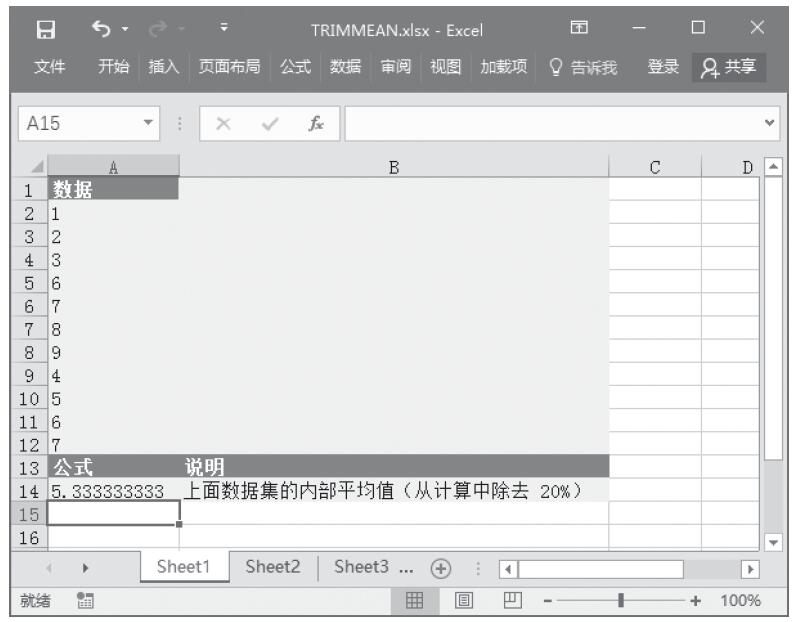
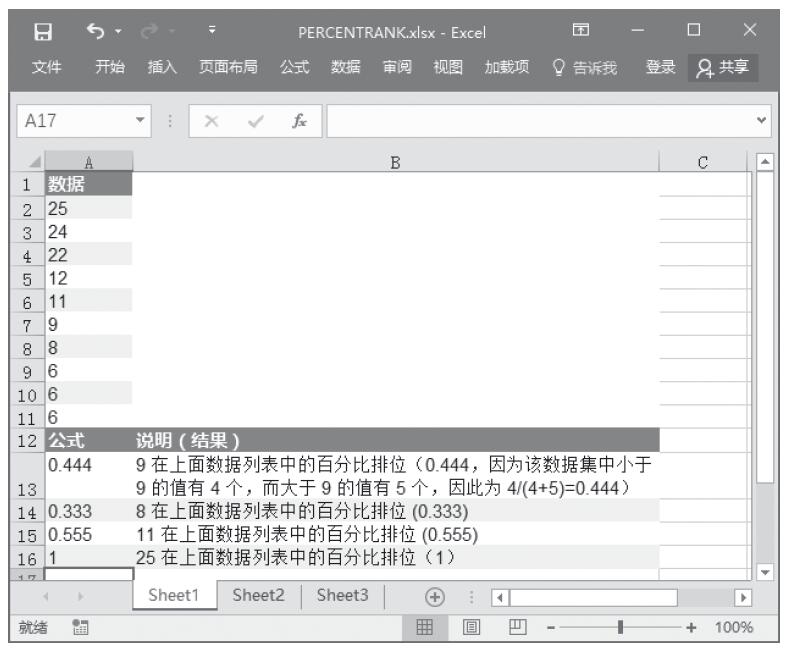
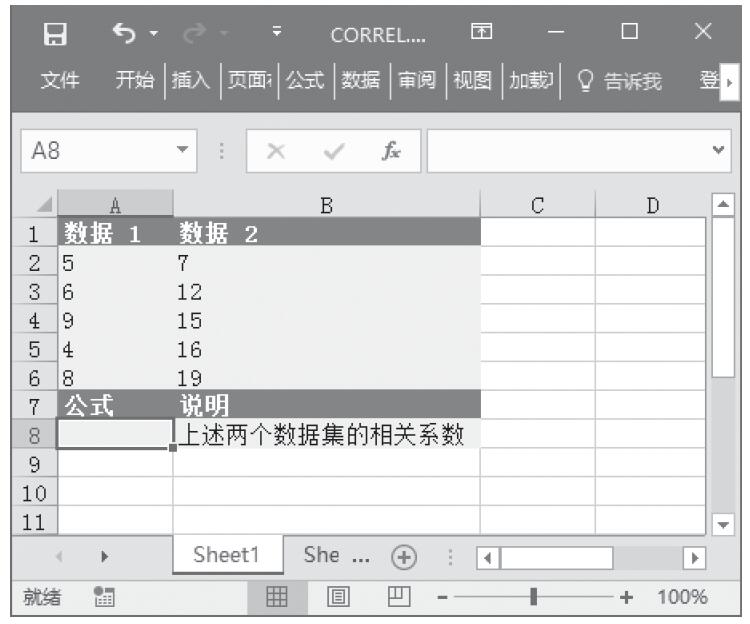
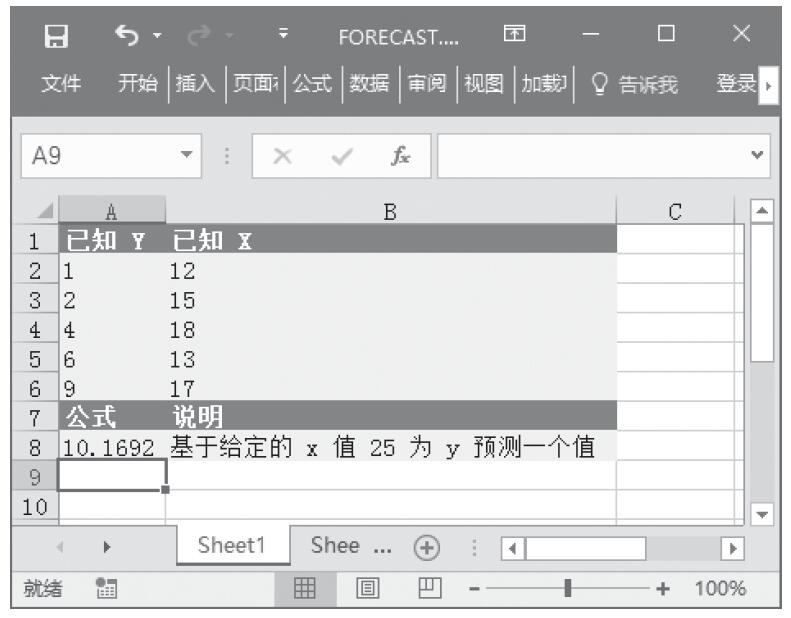
已知对应于双尾学生t分布的概率和自由度,计算学生t分布的t值。基础数据如图16-141所示。
步骤1:打开例子工作簿“TINV.xlsx”。
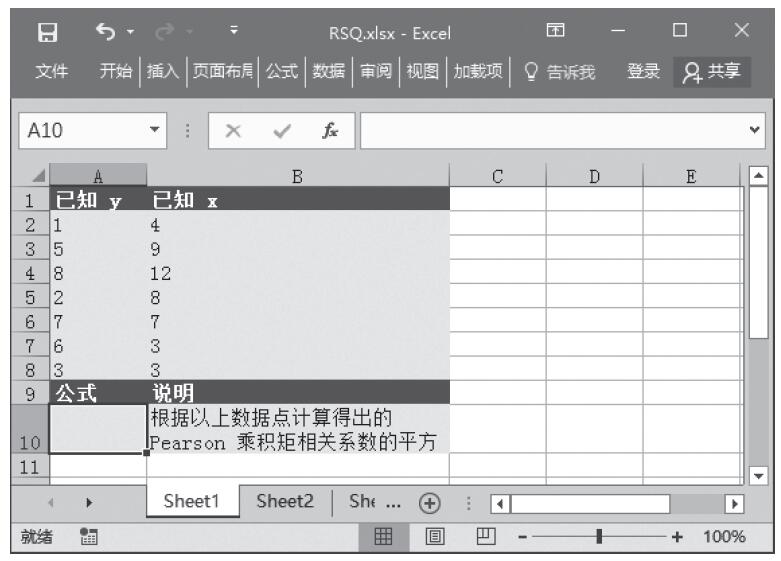
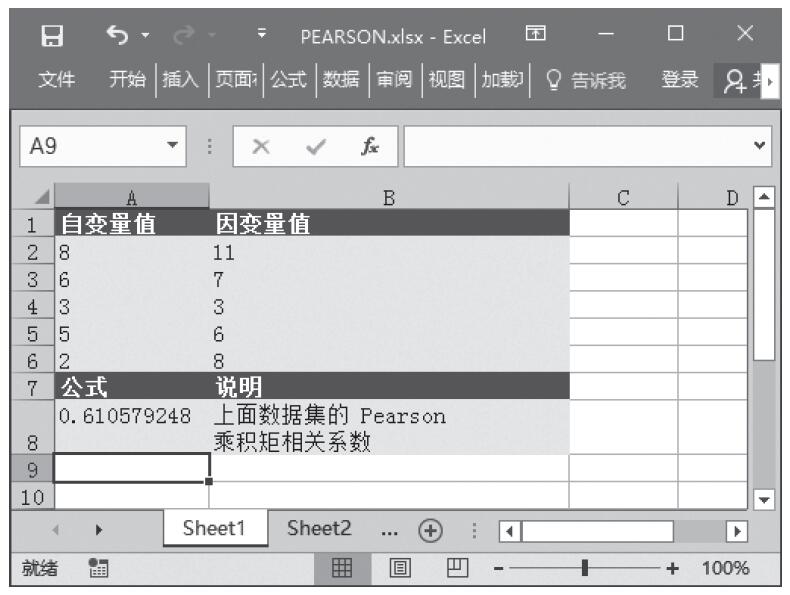
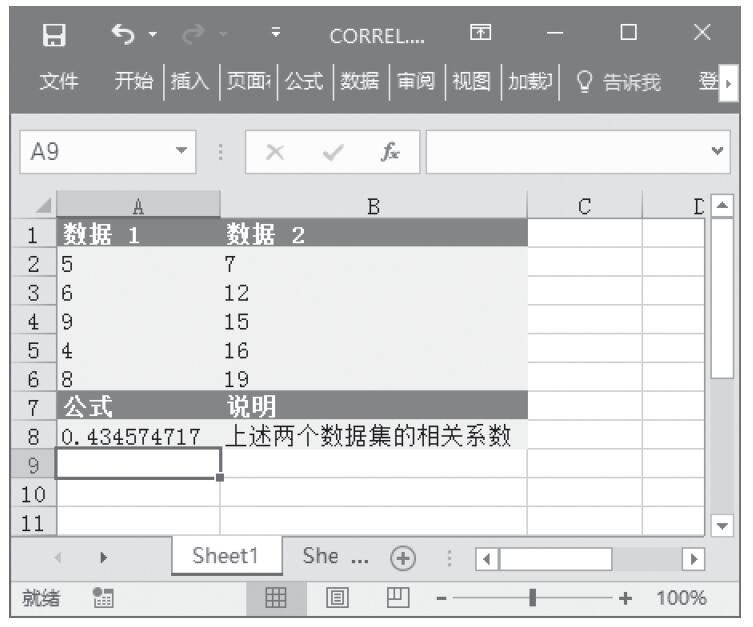
步骤2:在单元格A5中输入公式“=TINV(A2,A3)”,用于计算学生t分布的t值。计算结果如图16-142所示。
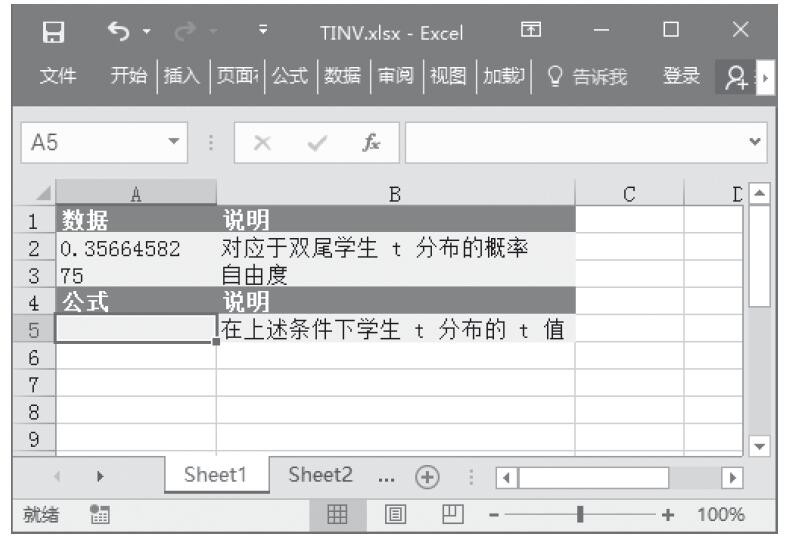
图16-141 基础数据
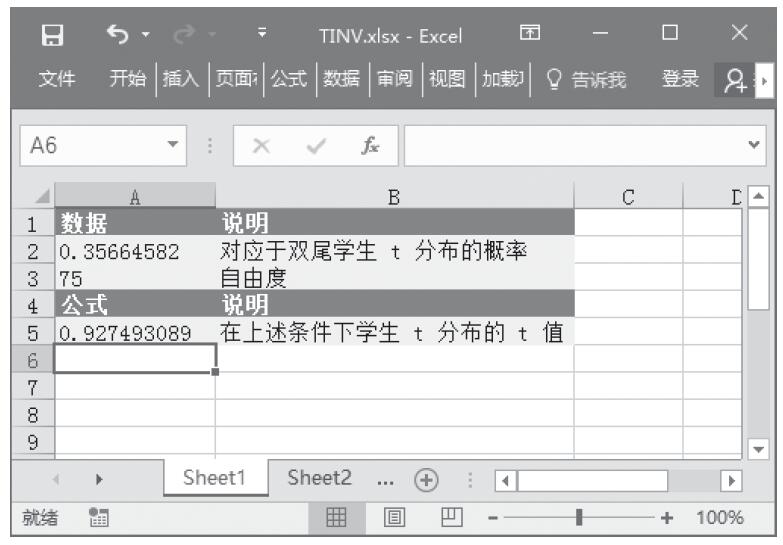
图16-142 计算结果
使用指南
如果任一参数为非数值型,函数TINV返回错误值“#VALUE!”;如果probability<0或probability>1,函数TINV返回错误值“#NUM!”;如果degrees_freedom不是整数,将被截尾取整;如果degrees_freedom<1,函数TINV返回错误值“#NUM!”。TINV返回t值,P(|X|>t)=probability,其中X为服从t分布的随机变量,且P(|X|>t)=P(X<-t or X>t)。
单尾t值可通过用两倍概率替换概率而求得。如果概率为0.05而自由度为10,则双尾值由TINV(0.05,10)计算得到,它返回2.28139。而同样概率和自由度的单尾值可由TINV(2*0.05,10)计算得到,它返回1.812462。在某些表中,概率被描述为(1-p)。
如果已给定概率值,则TINV使用TDIST(x,degrees_freedom,2)=probability求解数值x。因此,TINV的精度取决于TDIST的精度。TINV使用迭代搜索技术,如果搜索在100次迭代之后没有收敛,则函数返回错误值“#N/A”。