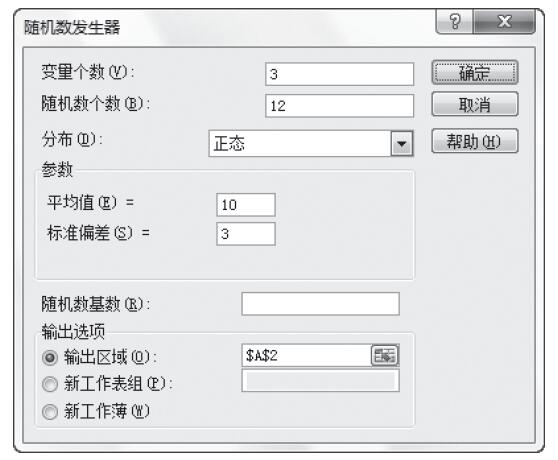
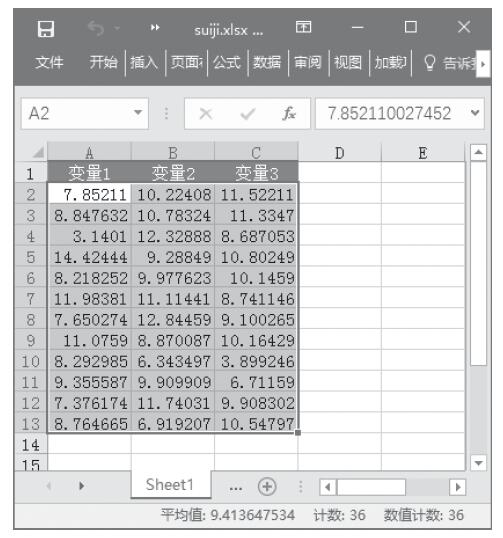
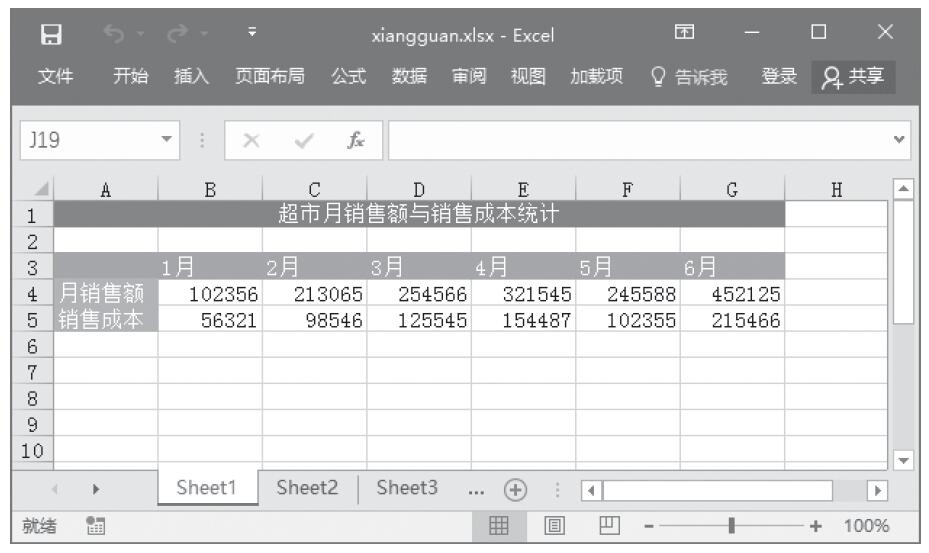
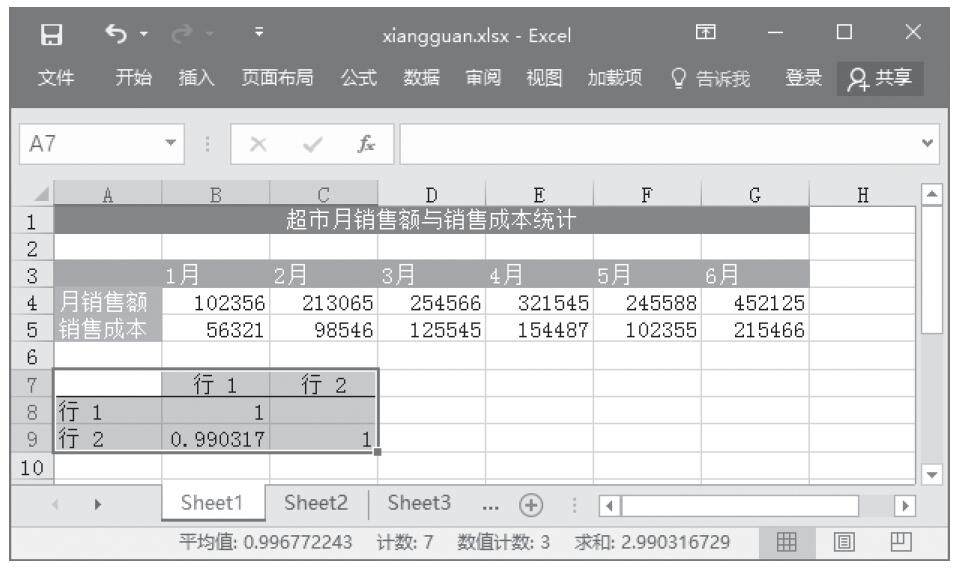
方差分析工具提供了以下3种不同类型的方差分析:单因素方差分析、包含重复的双因素方差分析和无重复的双因素方差分析。具体应该使用何种工具,需要根据因素的个数以及待检验样本总体中所含样本的个数而定。
单因素方差分析
单因素方差分析也叫作一维方差分析,此工具可对两个或更多样本的数据执行简单的方差分析。此分析可提供一种假设测试,该假设的内容是:每个样本都取自相同的基础概率分布,而不是对所有样本来说基础概率分布都不相同。如果只有两个样本,则可使用工作表函数TTEST。如果有两个以上的样本,则不能使用方便的TTEST归纳,可改为调用“单因素方差分析”模型。
下面通过实例说明如何进行单因素方差分析。
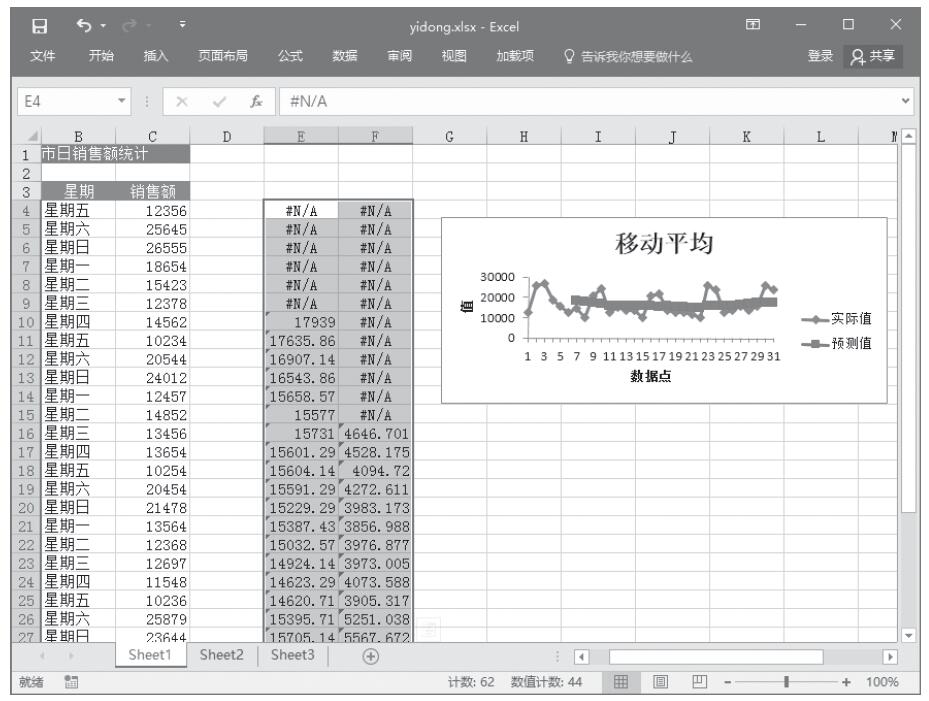
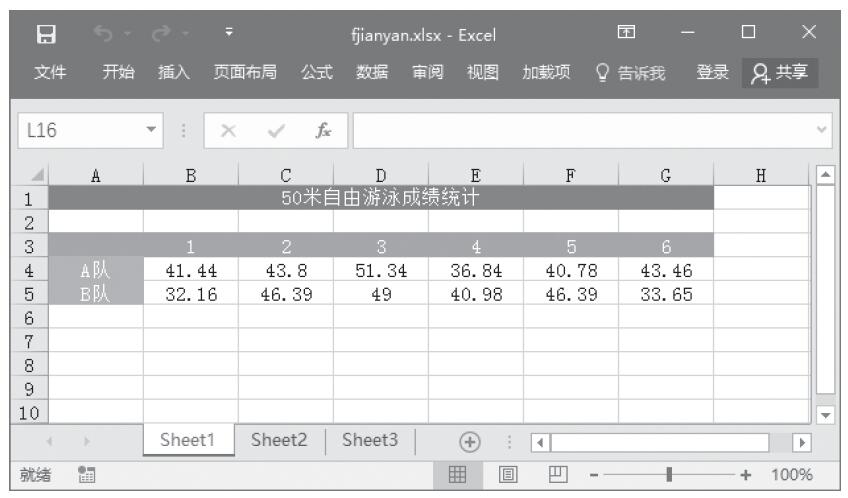
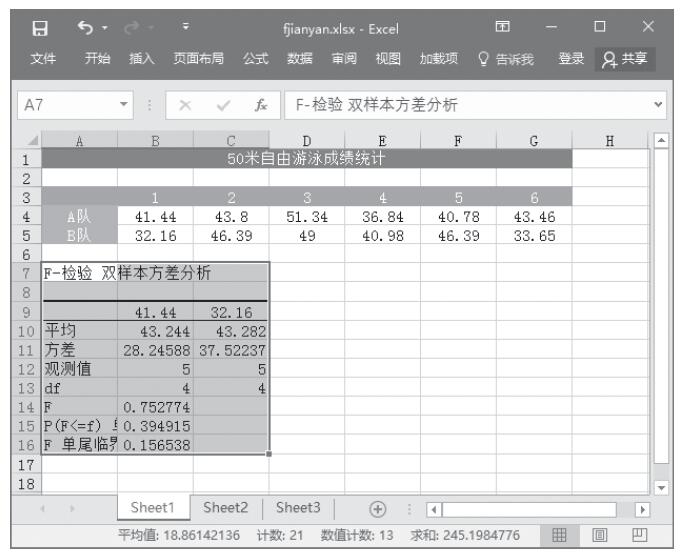
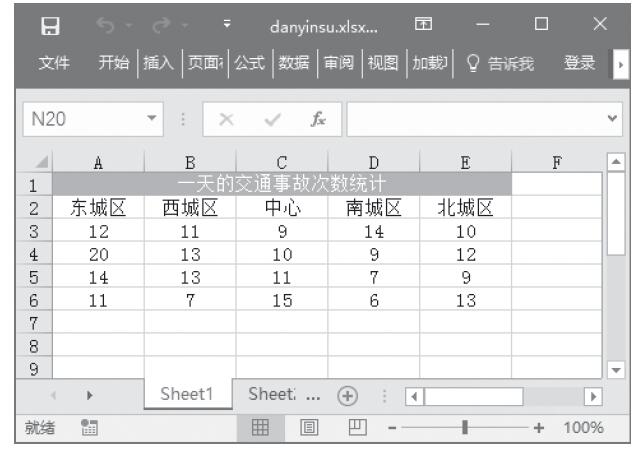
步骤1:将要处理的数据输入到工作表中,本例将5个地区一天当中发生交通事故的次数输入到工作表,如图22-15所示。下面将以α=0.01检验各地区平均每天交通事故的次数是否相等。
步骤2:单击“数据”选项卡,然后单击“分析”组中的“数据分析”命令,打开“数据分析”对话框。
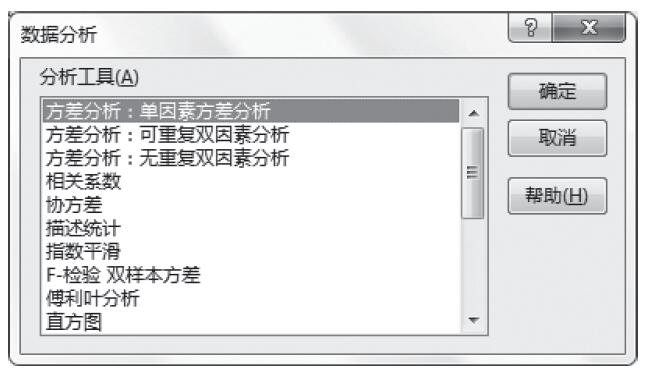
步骤3:选中“分析工具”列表中的“方差分析:单因素方差分析”,如图22-16所示。
图22-15 输入要处理的数据
图22-16 选中“方差分析:单因素方差分析”
步骤4:单击“确定”按钮,此时将打开“方差分析:单因素方差分析”对话框。
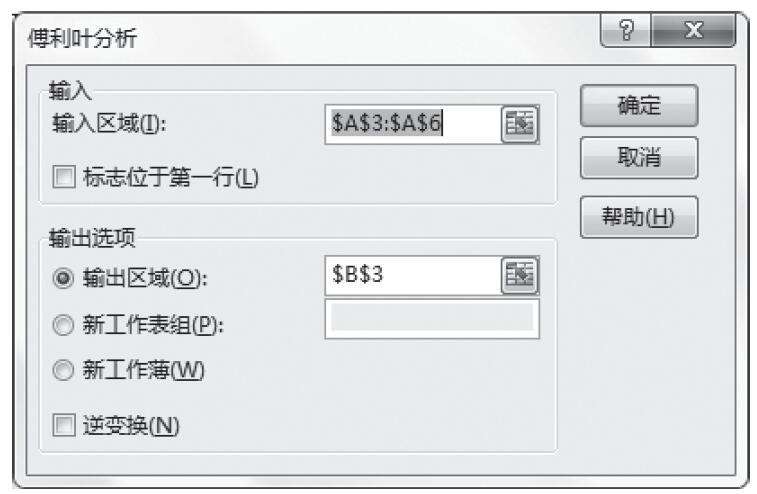
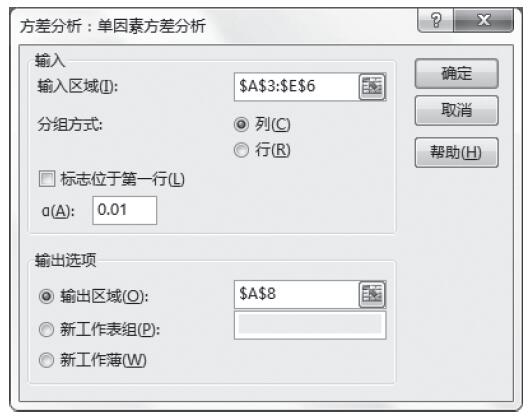
步骤5:在“输入区域”框中输入源数据区域“$A$3:$E$6”,将α设置为0.01,在“输出区域”框中输入“$A$8”,如图22-17所示。对话框中各选项简要介绍如下。
图22-17 单因素方差分析选项设置
- 输入区域:输入待分析数据区域的单元格引用,该引用必须由两个或两个以上按列或行排列的相应数据区域组成。
- 分组方式:如果要指定输入区域中的数据是按行还是按列排列,则选择“行”或“列”单选按钮。
- 标志位于第一行/标志位于第一列:如果输入区域的第一行中包含标志项,则选中“标志位于第一行”复选框。如果输入区域的第一列中包含标志项,则选中“标志位于第一列”复选框。如果输入区域没有标志项,则清除该复选框,Excel将在输出表中生成合适的数据标志。
- α:输入要用来计算F统计的临界值的置信度。α置信度为与I型错误发生概率相关的显著性水平(拒绝真假设)。
- 输出区域:输入对输出表左上角单元格的引用,Excel只在输出表的半边填写结果,这是因为两个区域中数据的协方差与区域被处理的次序无关。在输出表的对角线上为每个区域的方差。
- 新工作表组:选择此项可以在当前工作簿中插入新工作表,并由新工作表的A1单元格开始粘贴计算结果。如果要为新工作表命名,则在右侧的框中输入名称。
- 新工作簿:选择此项可以创建一个新的工作簿,并在新工作簿的新工作表中粘贴计算结果。
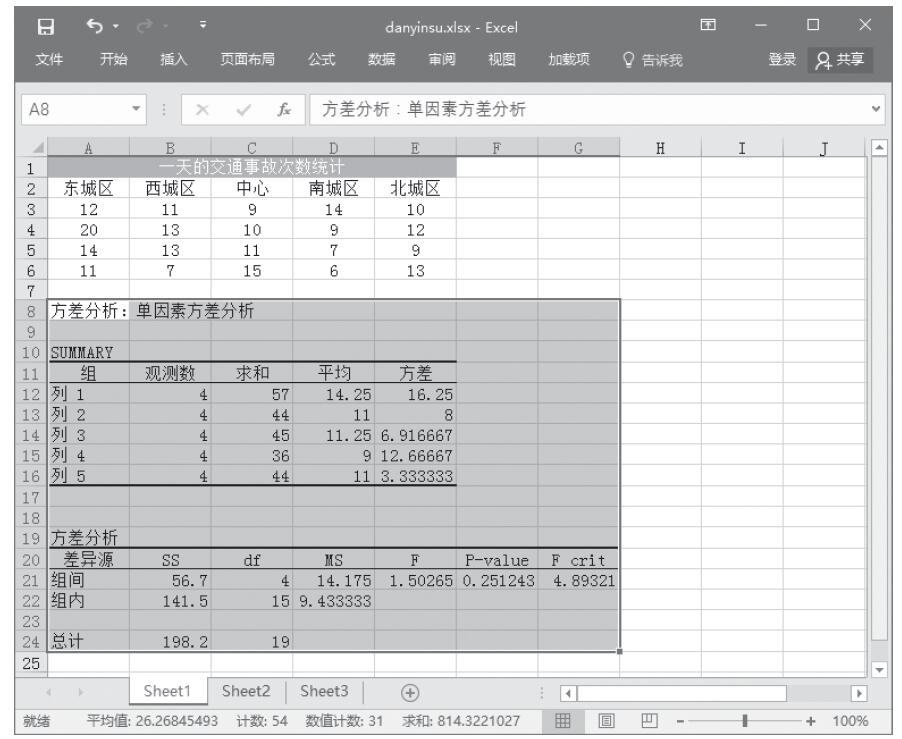
步骤6:单击“确定”按钮,即可从G1开始的单元格看到单因素方差分析的结果,如图22-18所示。
图22-18 单因素方差分析的结果
提示:由于F=0.124087591而Fα=5.952544683,因此F<Fα,这说明各地区每天的交通事故次数差异不显著。
包含重复的双因素方差分析
双因素方差分析用于观察两个因素的不同水平对所研究对象的影响是否存在明显的不同,根据是否考虑两个因素的交互作用,又可以分为“包含重复的双因素方差分析”和“无重复的双因素方差分析”。本节首先介绍“包含重复的双因素方差分析”。
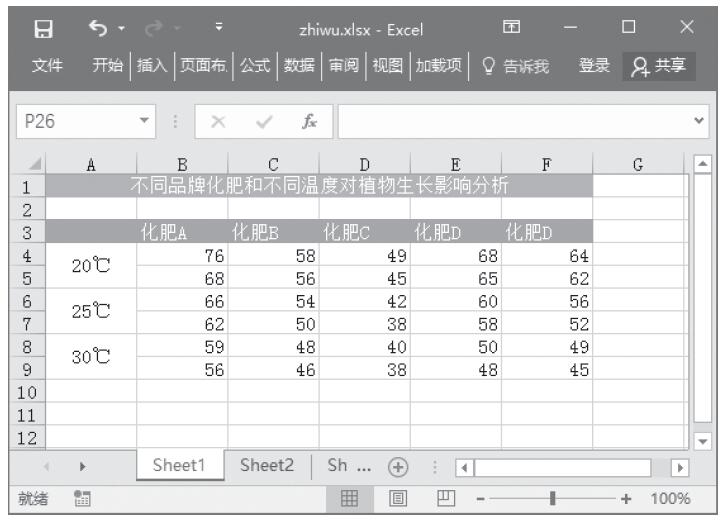
例如,在测量植物生长高度的实验中,共施用了5种不同品牌的化肥(A、B、C、D、E),同时植物处于不同温度(20℃、25℃、30℃)的环境中。对于每种化肥与每种温度的组合各统计两次,测定结果如图22-19所示。
图22-19 统计数据
使用“包含重复的双因素方差分析”可以检验:
- 施用不同化肥的植物高度是否取自相同的基础样本总体,此分析忽略温度。
- 处于不同温度级别环境中的植物高度是否取自相同的基础样本总体,此分析忽略所使用的化肥品牌。
无论是否考虑上述不同品牌化肥之间的差异的影响以及不同温度之间差异的影响,代表所有{化肥,温度}值对的样本都取自相同的样本总体。另一种假设是除了基于化肥或温度单个因素的差异带来的影响之外,特定的{化肥,温度}值对也会有影响。
下面通过实例介绍进行包含重复的双因素方差分析的具体操作步骤。
步骤1:将要处理的数据按图22-19所示输入到工作表中。
步骤2:单击“数据”选项卡,然后单击“分析”组中的“数据分析”命令,打开“数据分析”对话框。
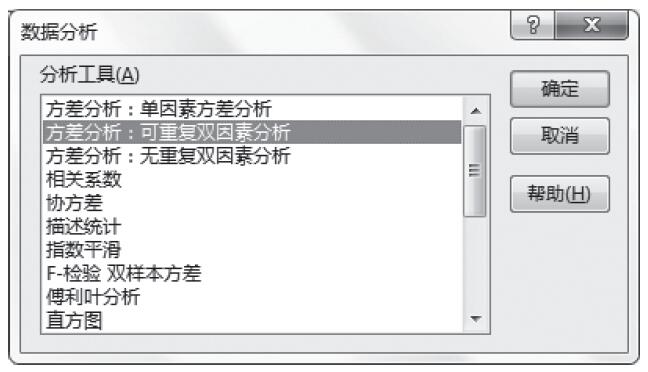
步骤3:选中“分析工具”列表中的“方差分析:可重复双因素分析”,如图22-20所示。
图22-20 选中“方差分析:可重复双因素分析”
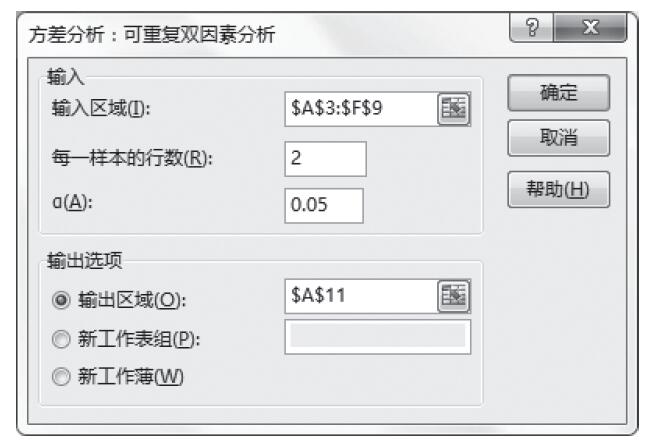
图22-21 “方差分析:可重复双因素分析”对话框
步骤4:单击“确定”按钮,打开“方差分析:可重复双因素分析”对话框。
步骤5:在“输入区域”框中输入源数据区域,在“每一样本的行数”框中输入每一样本的重复次数(本例中为2),将α值设置为0.05,将设置“输出区域”,如图22-21所示。
提示:在“每一样本的行数”框中输入包含在每个样本中的行数。每个样本必须包含同样的行数,因为每一行代表数据的一个副本。
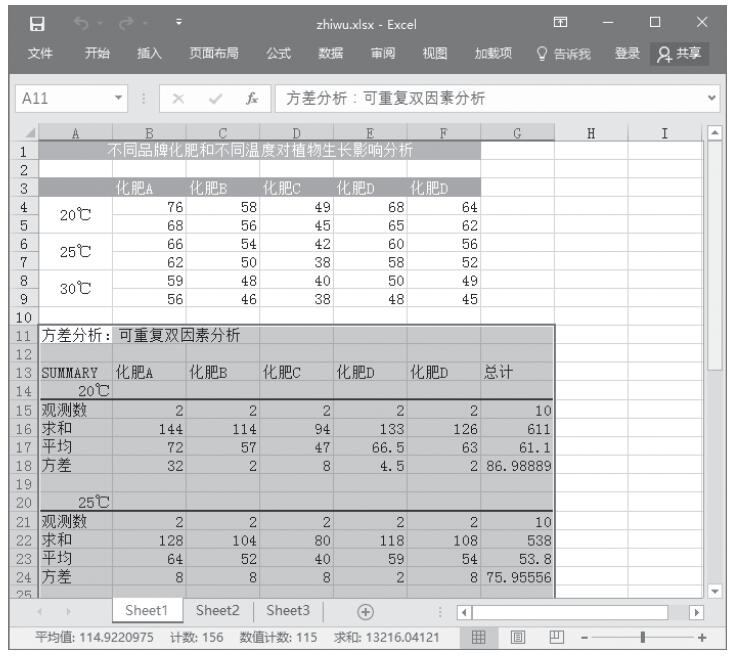
步骤6:单击“确定”按钮,即可看到分析的结果,如图22-22所示。
图22-22 可重复双因素方差分析结果
无重复的双因素方差分析
此分析工具可用于当数据像可重复双因素那样按照两个不同维度进行分类时的情况,只是此工具假设每一对值只有一个观察值,如在上面的示例中的每个{化肥,温度}值对。下面通过实例说明如何进行无重复的双因素方差分析。
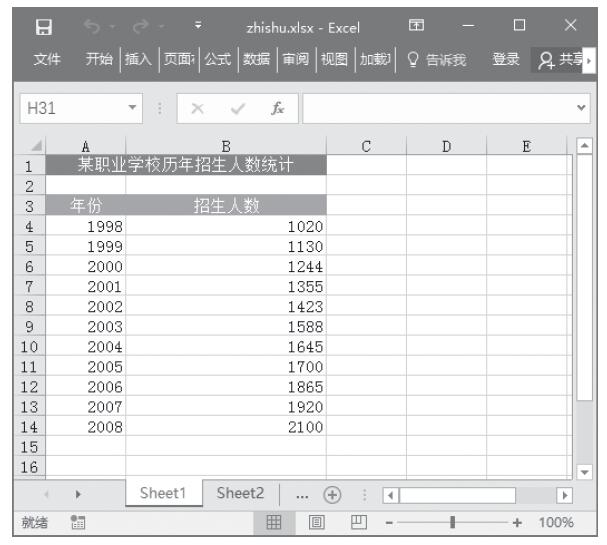
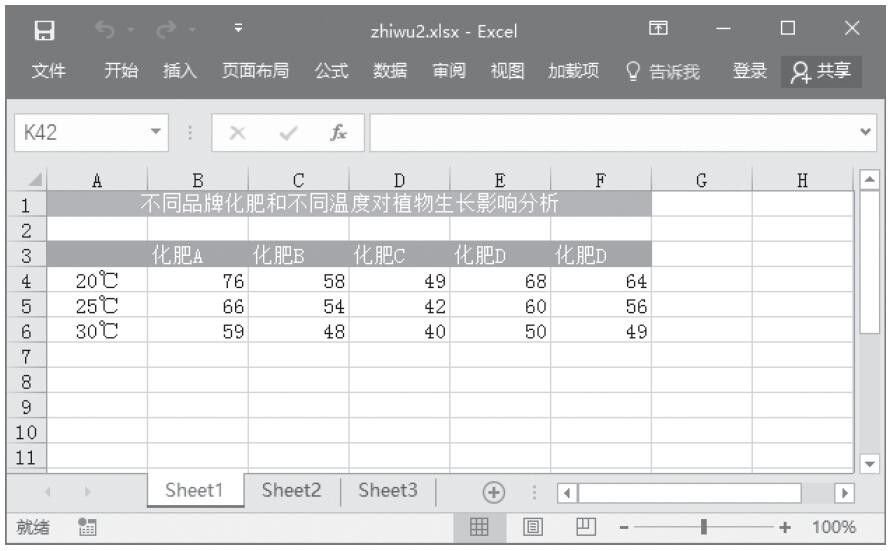
步骤1:将要处理的数据按图22-23所示输入到工作表中。
图22-23 将要处理的数据输入到工作表中
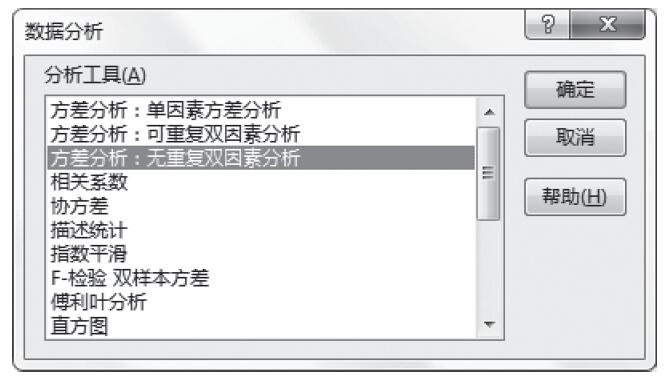
图22-24 选中“方差分析:无重复双因素分析”
步骤2:单击“数据”选项卡,然后单击“分析”组中的“数据分析”命令,打开“数据分析”对话框。
步骤3:选中“分析工具”列表中的“方差分析:无重复双因素分析”,如图22-24所示。
步骤4:单击“确定”按钮,打开“方差分析:无重复双因素分析”对话框。
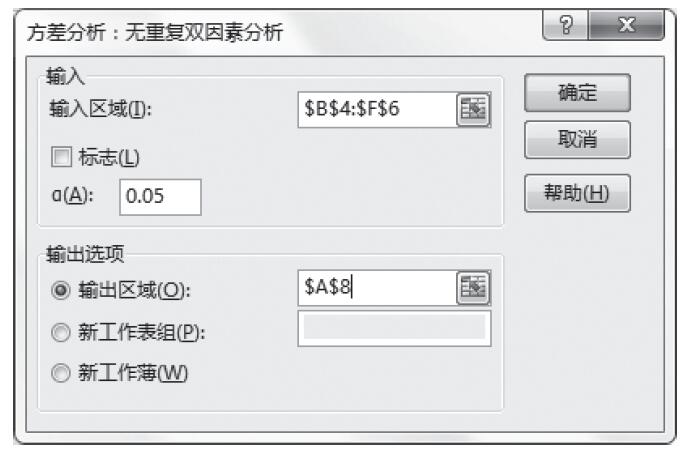
步骤5:在“输入区域”框中输入源数据区域,将α值设置为0.05,并设置“输出区域”,如图22-25所示。
图22-25 “方差分析:无重复双因素分析”对话框
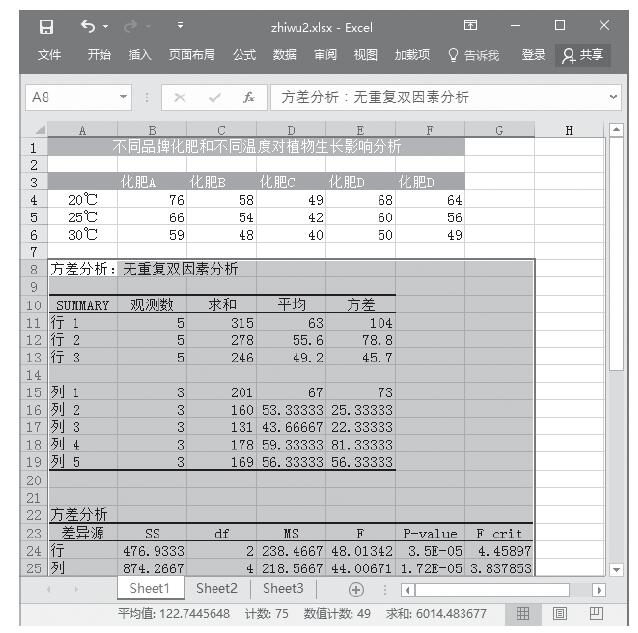
步骤6:单击“确定”按钮,即可看到分析的结果,如图22-26所示。
图22-26 无重复双因素方差分析结果