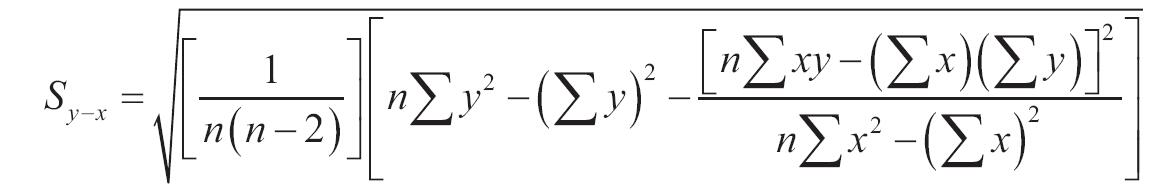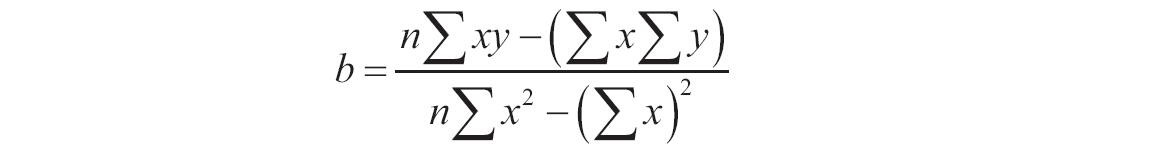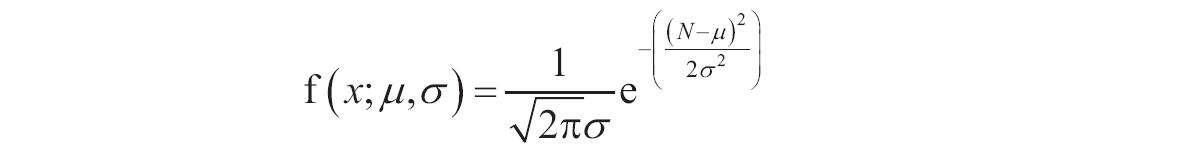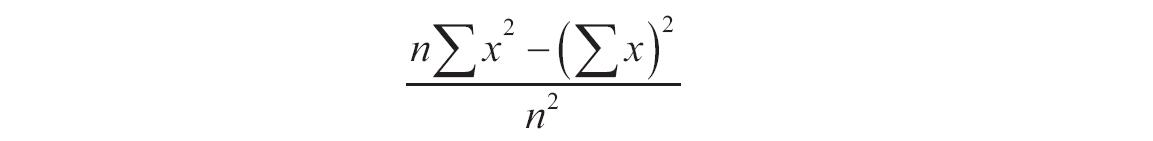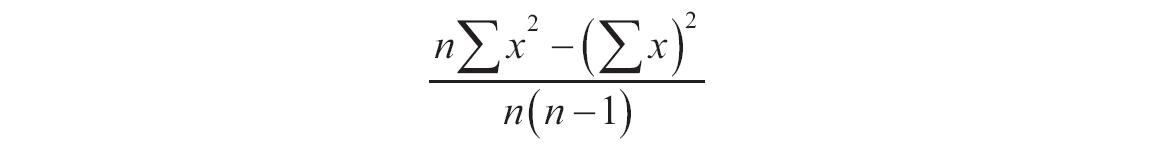INTERCEPT函数用于利用现有的x值与y值计算直线与y轴的截距。截距为穿过已知的known_x’s和known_y’s数据点的线性回归线与y轴的交点。当自变量为0(零)时,使用INTERCEPT函数可以决定因变量的值。例如,当所有的数据点都是在室温或更高的温度下取得的,可以用INTERCEPT函数预测在0℃时金属的电阻。INTERCEPT函数的语法如下。
INTERCEPT(known_y's,known_x's)
其中参数known_y’s为因变量的观察值或数据集合,known_x’s为自变量的观察值或数据集合。
典型案例
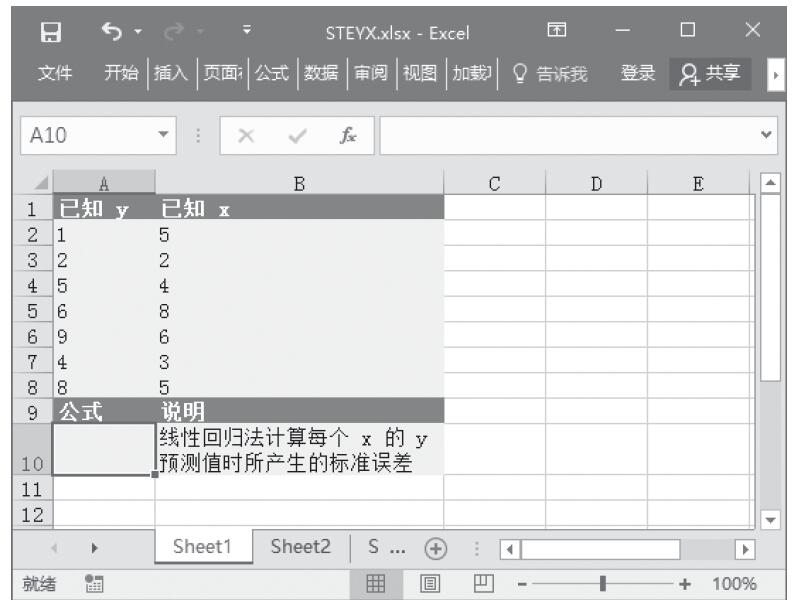
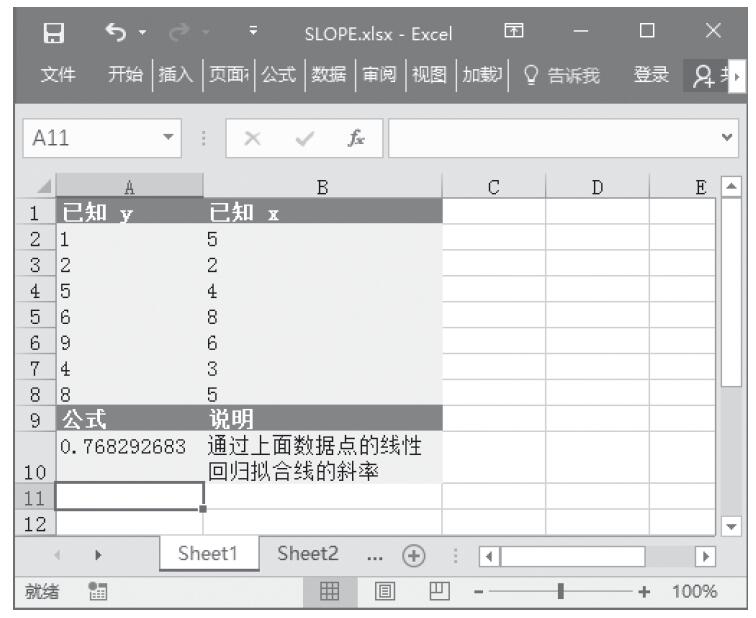
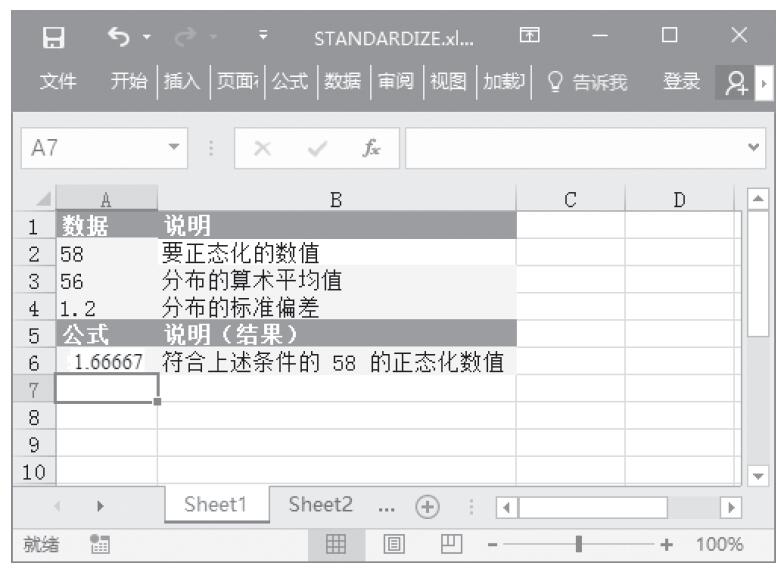
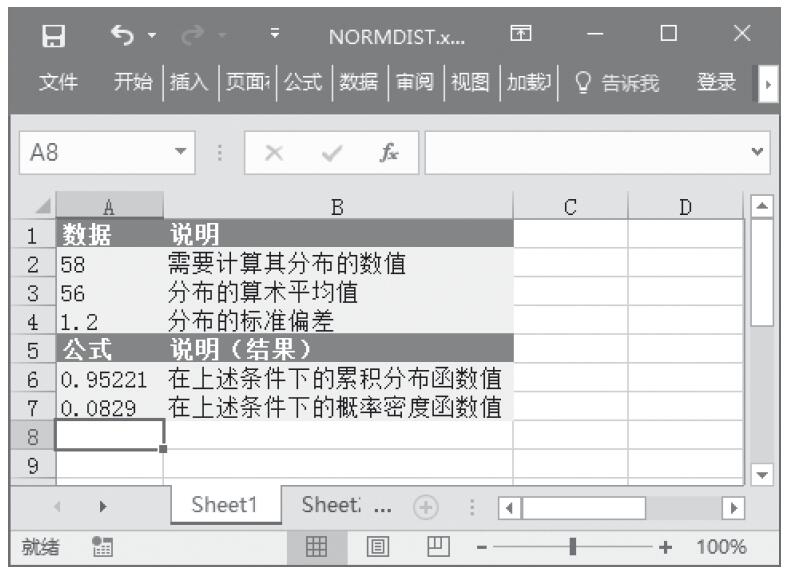
已知一组x、y值,计算直线与y轴的截距。基础数据如图16-117所示。
步骤1:打开例子工作簿“INTERCEPT.xlsx”。
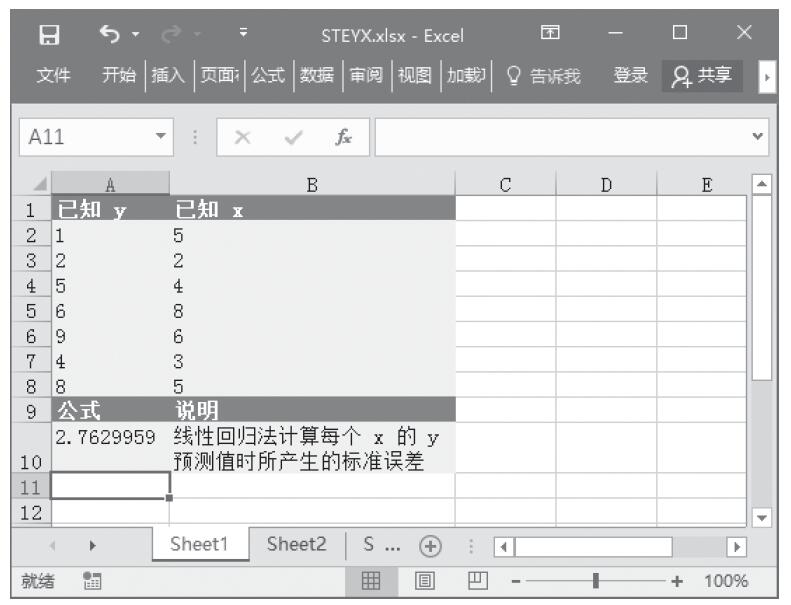
步骤2:在单元格A8中输入公式“=INTERCEPT(A2:A6,B2:B6)”,用于计算已知直线与y轴的截距。计算结果如图16-118所示。
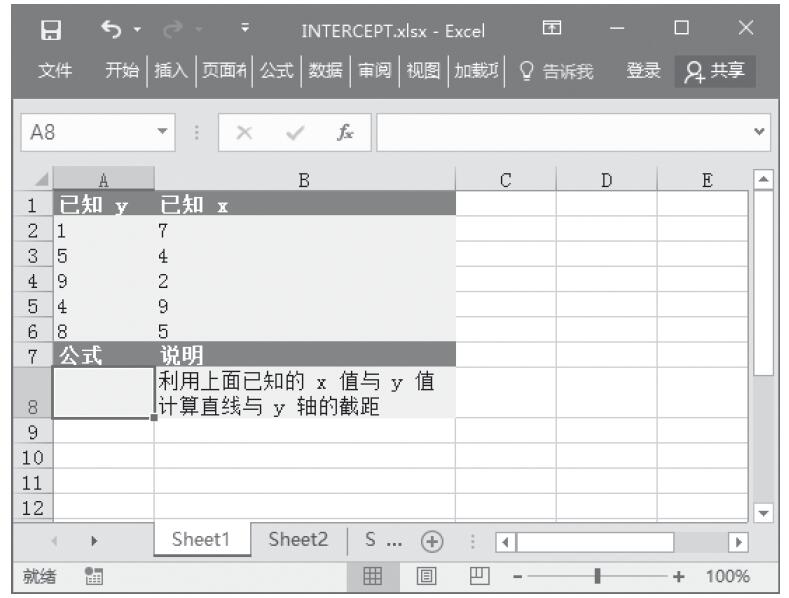
图16-117 基础数据
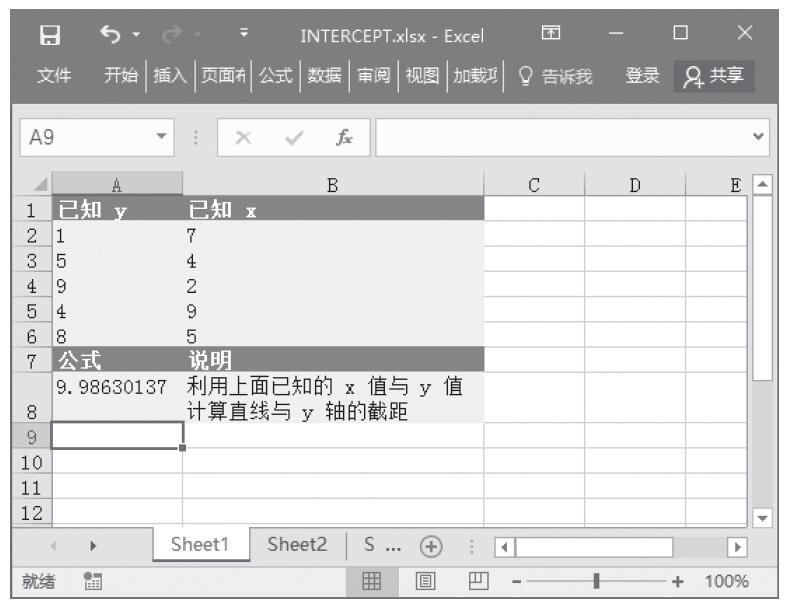
图16-118 计算结果
使用指南
参数可以是数字,或者是包含数字的名称、数组或引用。如果数组或引用参数包含文本、逻辑值或空白单元格,则这些值将被忽略,但包含零值的单元格将计算在内。如果known_y’s和known_x’s所包含的数据点个数不相等或不包含任何数据点,则函数INTERCEPT返回错误值“#N/A”。回归线a的截距公式为:
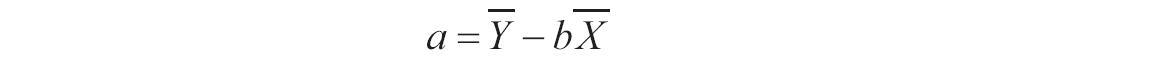
公式中斜率b计算如下:
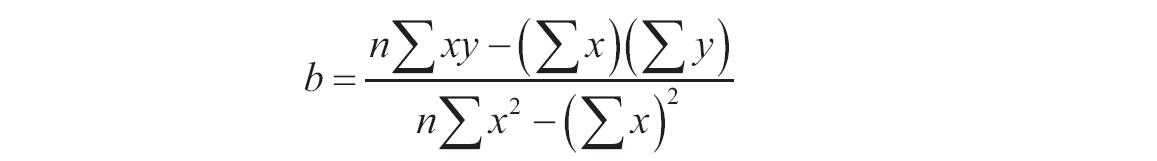
其中x和y是样本平均值AVERAGE(known_x’s)和AVERAGE(known_y’s)。
函数SLOPE和INTERCEPT中使用的下层算法与函数LINEST中使用的下层算法不同。当数据未定且共线时,这些算法之间的差异会导致不同的结果。例如,如果参数known_y’s的数据点为0,参数known_x’s的数据点为1:
·SLOPE和INTERCEPT返回错误“#DIV/0!”。INTERCEPT和SLOPE算法用来查找一个且仅一个答案,在这种情况下可能有多个答案。
·LINEST返回值0。LINEST算法用来返回共线数据的合理结果,在这种情况下至少可找到一个答案。