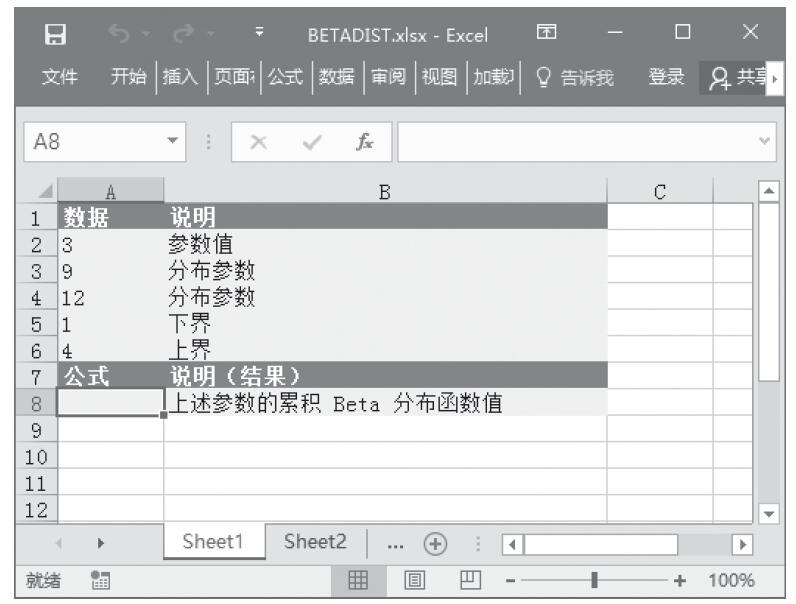
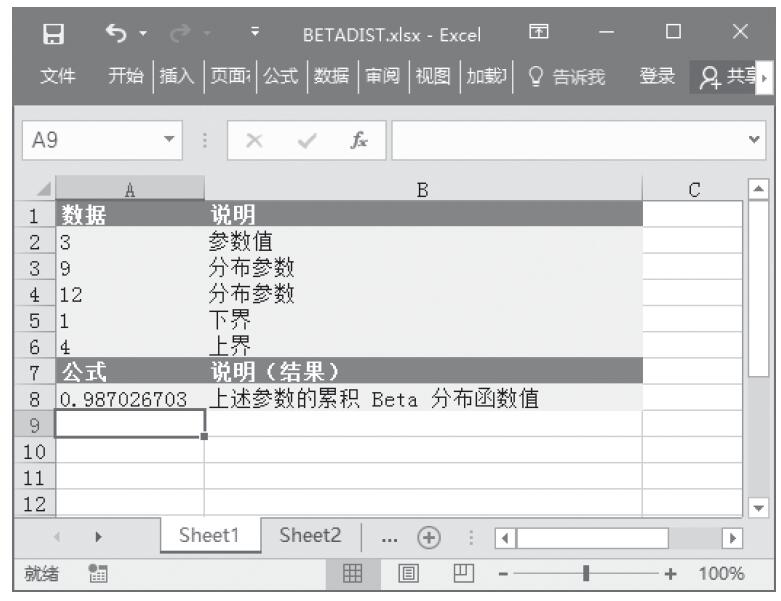
FTEST函数用于计算F检验的结果。F检验返回的是当数组1和数组2的方差无明显差异时的单尾概率。可以使用FTEST函数来判断两个样本的方差是否不同。例如,给定几个不同学校的测试成绩,可以检验学校间测试成绩的差别程度。FTEST函数的语法如下。
FTEST(array1,array2)
其中参数array1为第一个数组或数据区域,array2为第二个数组或数据区域。
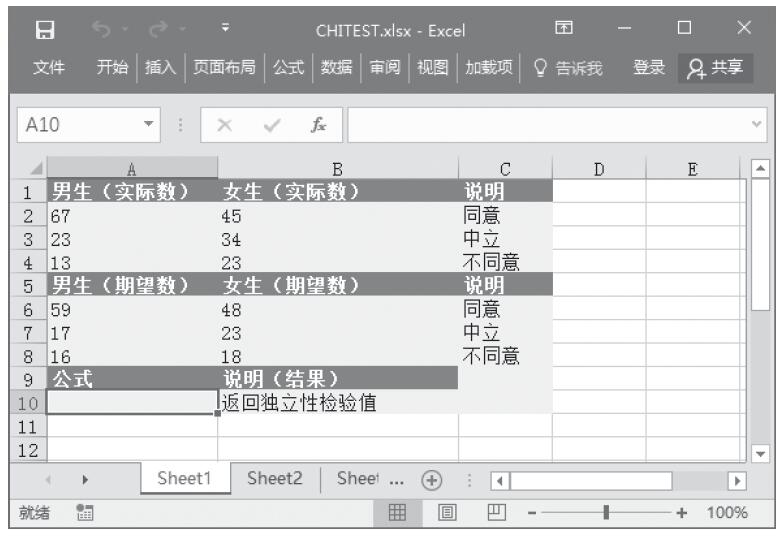
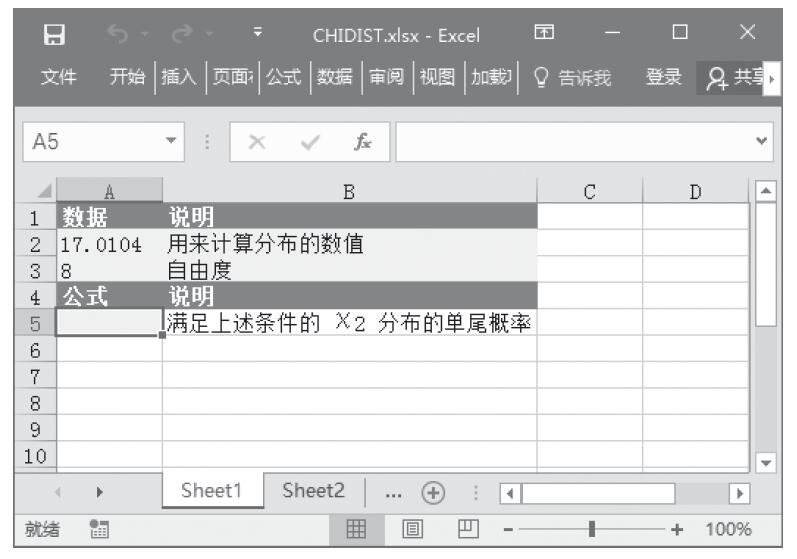
【典型案例】已知在两个数据区域中,给定了两个不同学校不同科目在某一测试中成绩达到优秀分数线的学生数目,计算学校间测试成绩的差别程度。基础数据如图16-37所示。
步骤1:打开例子工作簿“FTEST.xlsx”。
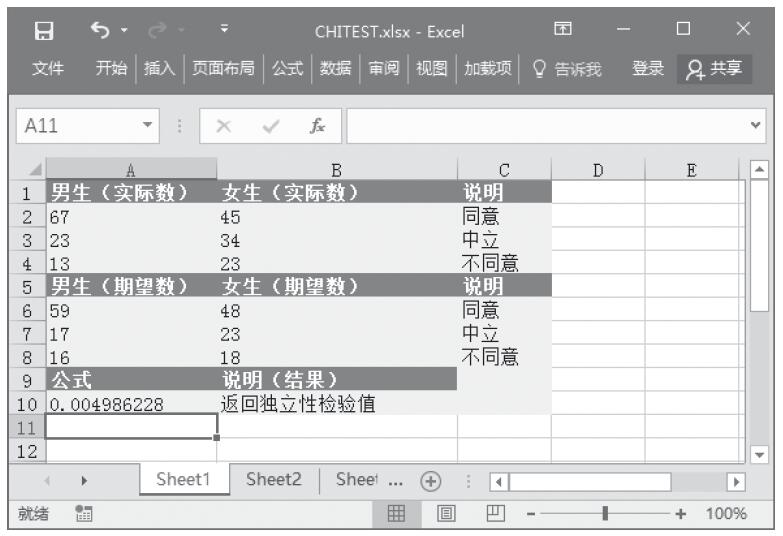
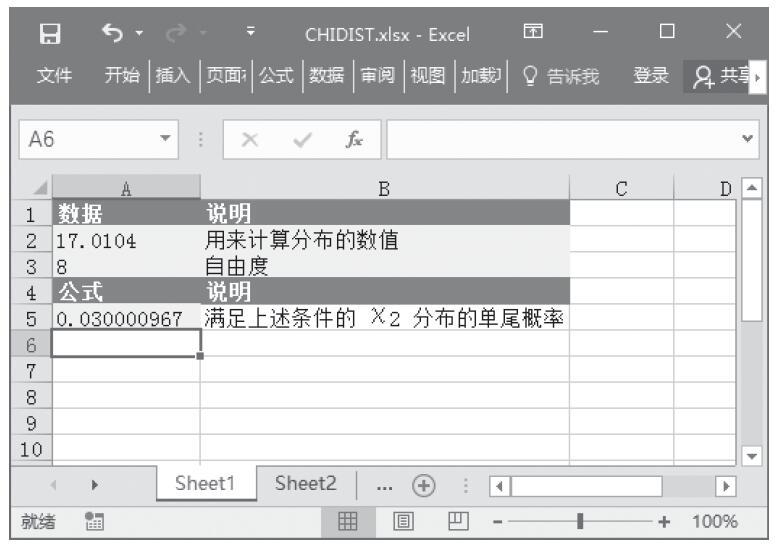
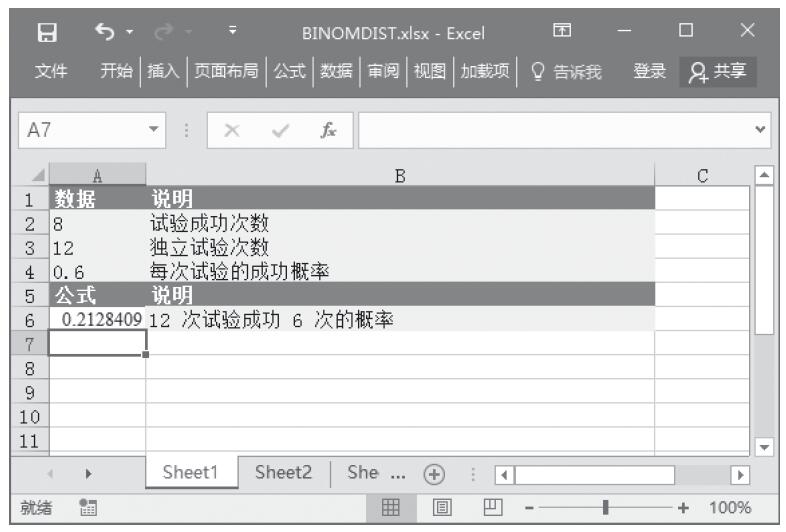
步骤2:在单元格A8中输入公式“=FTEST(A2:A6,B2:B6)”,用于计算总体平均值的置信区间。计算结果如图16-38所示。
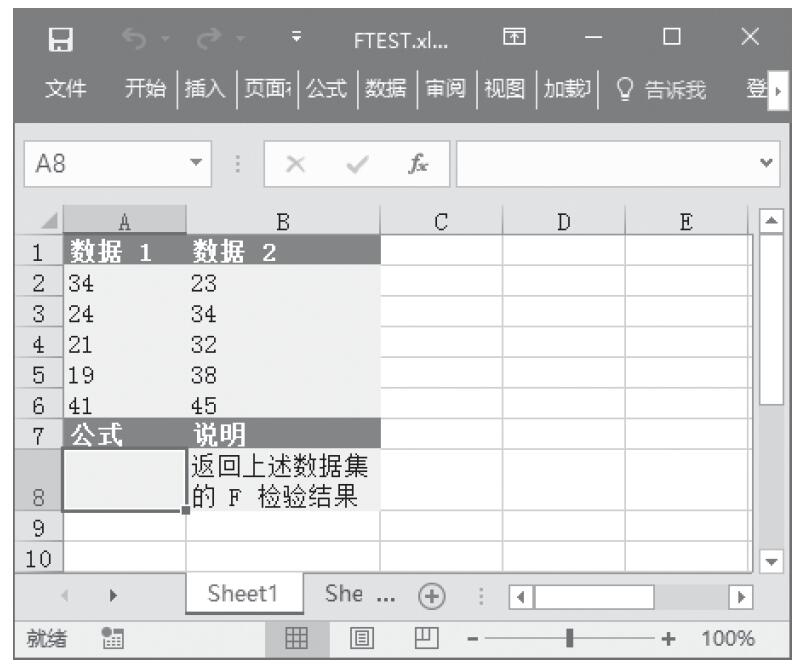
图16-37 基础数据
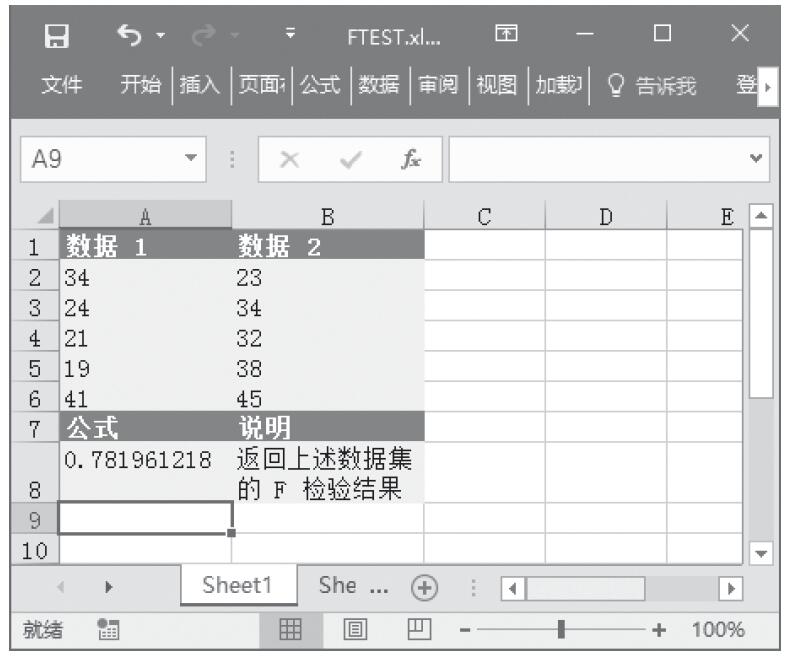
图16-38 计算结果
【使用指南】参数可以是数字,或者是包含数字的名称、数组或引用。如果数组或引用参数包含文本、逻辑值或空白单元格,则这些值将被忽略;但包含零值的单元格将计算在内。如果数组1或数组2中数据点的个数小于2个,或者数组1或数组2的方差为零,函数FTEST返回错误值“#DIV/0!”。
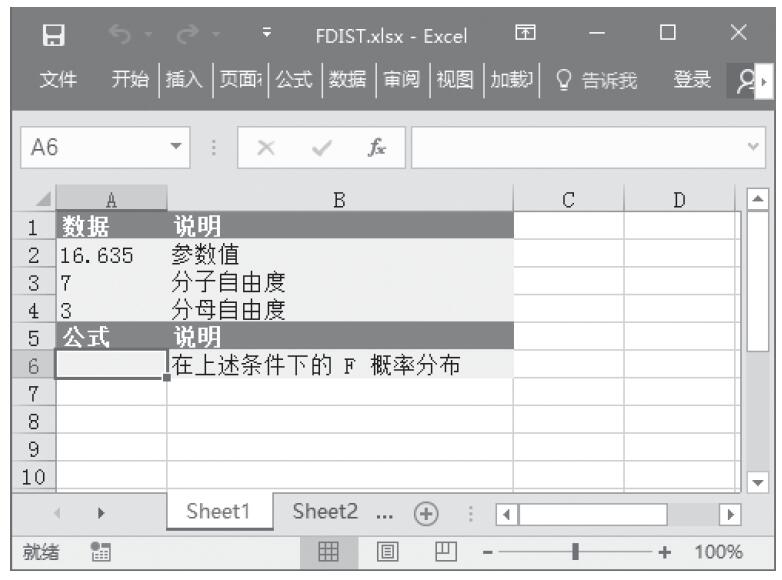
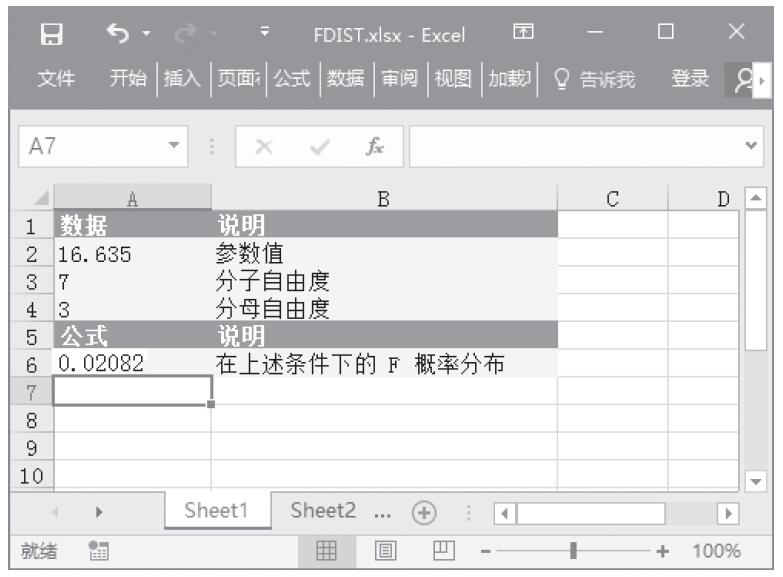
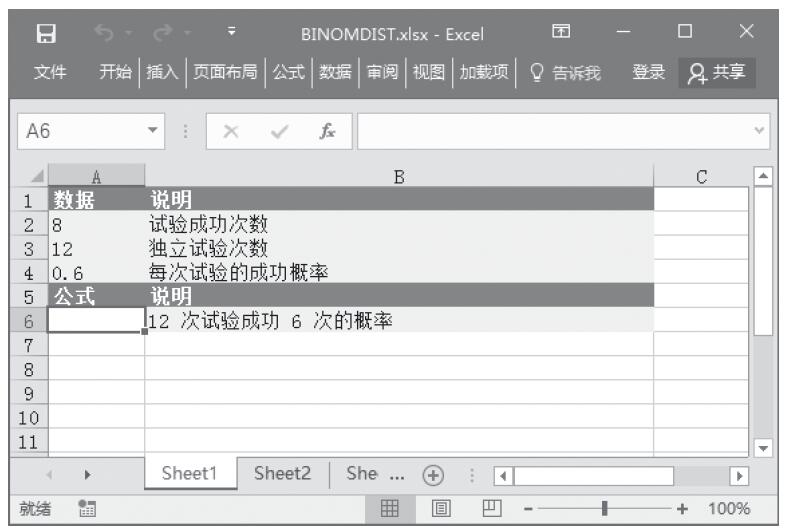
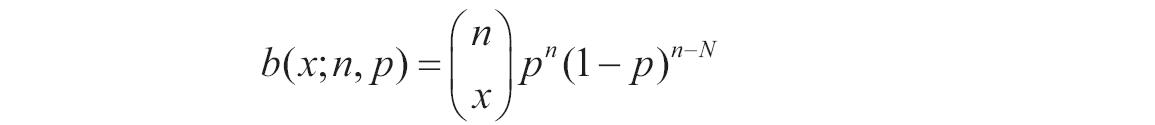
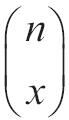 等于COMBIN(n,x)。
等于COMBIN(n,x)。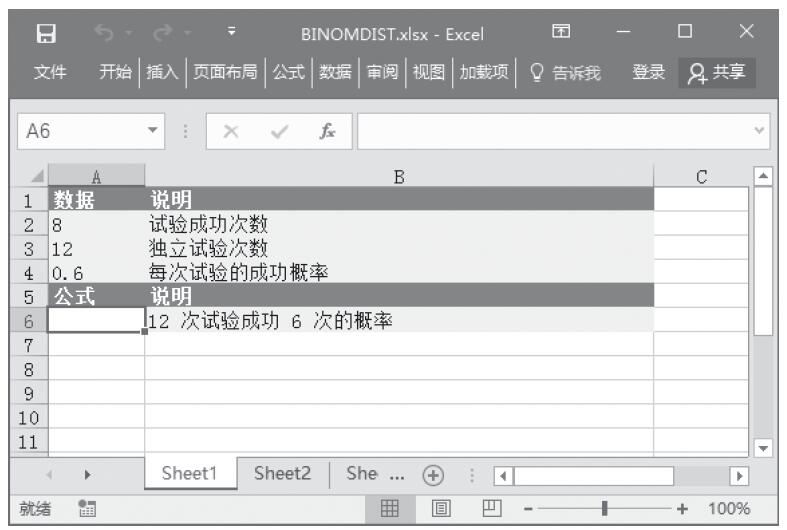
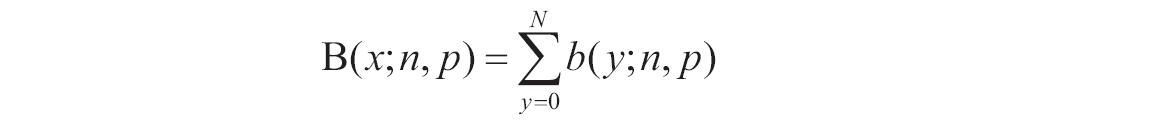
 检验
检验